DeepSeek发布推理系统概览,成本利润率高达545%
AI导读:
DeepSeek官方账号在知乎首次发布推理系统概览,公开核心优化方案及财务数据,理论上一天总收入可达$562,027,成本利润率高达545%。所有服务均采用H800 GPU,通过动态调整节点资源实现效率最大化。
3月1日,Deepseek官方账号在知乎首次发布《DeepSeek-V3/R1推理系统概览》技术文章,公开了其推理系统的核心优化方案及成本利润率等关键财务数据,这一举动引发了业内的广泛关注。据DeepSeek透露,若所有tokens均按DeepSeek R1的定价计算,理论上一天的总收入可达$562,027,成本利润率高达545%。
DeepSeek官方指出,DeepSeek V3和R1的所有服务均采用H800 GPU,并使用与训练一致的精度,以确保服务效果的最大化。同时,通过动态调整节点资源,实现了效率的最优化。
在最近24小时(北京时间2025/02/27 12:00至2025/02/28 12:00)内,DeepSeek V3和R1推理服务占用的节点总和达到峰值278个,平均占用226.75个节点(每个节点含8个H800 GPU)。假设GPU租赁成本为2美金/小时,则每天的总成本为$87,072。
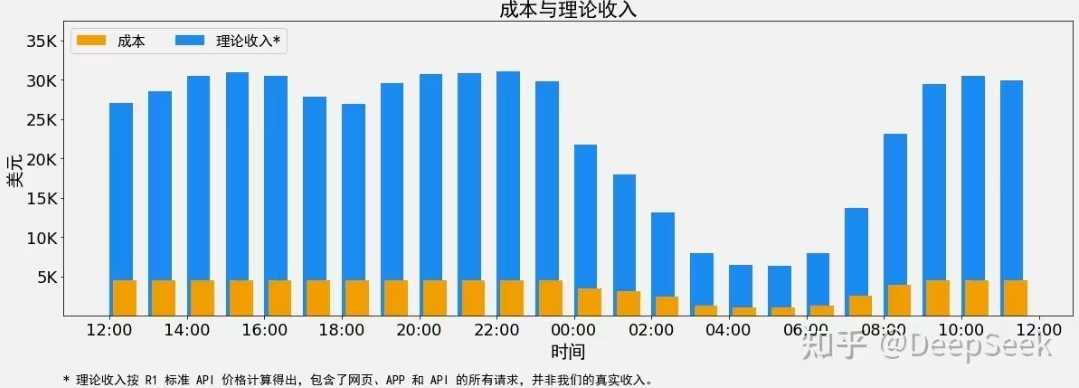
DeepSeek进一步透露,若所有tokens均按DeepSeek R1的定价计算,理论上一天的总收入为$562,027,成本利润率高达545%。其中,DeepSeek R1的定价为:$0.14/百万输入tokens(缓存命中),$0.55/百万输入tokens(缓存未命中),$2.19/百万输出tokens。然而,DeepSeek也承认实际收入并未达到这一水平,因为V3的定价更低,且收费服务仅占一部分,夜间还会有折扣。
此外,DeepSeek还公布了DeepSeek-V3/R1推理系统的概述。为实现更大的推理吞吐量与更低的延迟,DeepSeek采用了大规模跨节点专家并行(Expert Parallelism / EP)方案。EP不仅使batch size大幅增加,提高了GPU矩阵乘法的效率,还使专家分散在不同的GPU上,降低了延迟。通过EP增大batch size、隐藏通信延迟于计算之后,并执行负载均衡,DeepSeek成功应对了EP带来的系统复杂性挑战。
(文章来源:广州日报)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。





