DeepSeek发布原生稀疏注意力技术,挑战ChatGPT性能
AI导读:
DeepSeek发布原生稀疏注意力(NSA)技术,提升长文本处理速度11.6倍,超越传统全注意力模型性能。同时,月之暗面发布MoBA方法,优化长文算法。DeepSeek还对现有计算机硬件进行优化,为未来开源和广泛应用奠定基础。
北京时间2月18日,在马斯克庆祝Grok 3模型发布之际,Deepseek在社交平台X上发布了一篇技术论文,聚焦原生稀疏注意力(Native Sparse Attention,NSA),直接挑战ChatGPT等顶尖大模型背后的Transformer架构的注意力机制。
通过NSA技术,DeepSeek不仅将大语言模型处理64k长文本的速度提升了最高11.6倍,还在通用基准测试中超越了传统全注意力模型(Full Attention models)的性能。这一突破引发业界关注。
值得注意的是,论文由DeepSeek创始人梁文锋亲自提交,并作为作者之一。同一天,月之暗面创始人杨植麟也发布了新论文,提出块注意力混合(Mixture of Block Attention,MoBA)方法,旨在优化长文算法。
MoBA方法结合了全注意力和稀疏注意力机制,允许模型在两者之间切换,为全注意力模型提供更多适配空间。DeepSeek的NSA机制则强调通过算法优化提升长文处理效率,不专注于每个单词,而是关注重要单词以提升效率。
DeepSeek介绍称,NSA专为长文本训练与推理设计,通过动态分层稀疏策略等方法,显著优化了AI模型在训练和推理过程中的表现,特别是提升了长上下文的推理能力,在保证性能的同时提高了推理速度,降低了预训练成本。

图片来源:X
梁文锋不仅参与了论文的撰写,还亲自将其提交至预印本网站。论文的第一作者是DeepSeek的实习生袁景阳,他参与了多项DeepSeek的研究工作。
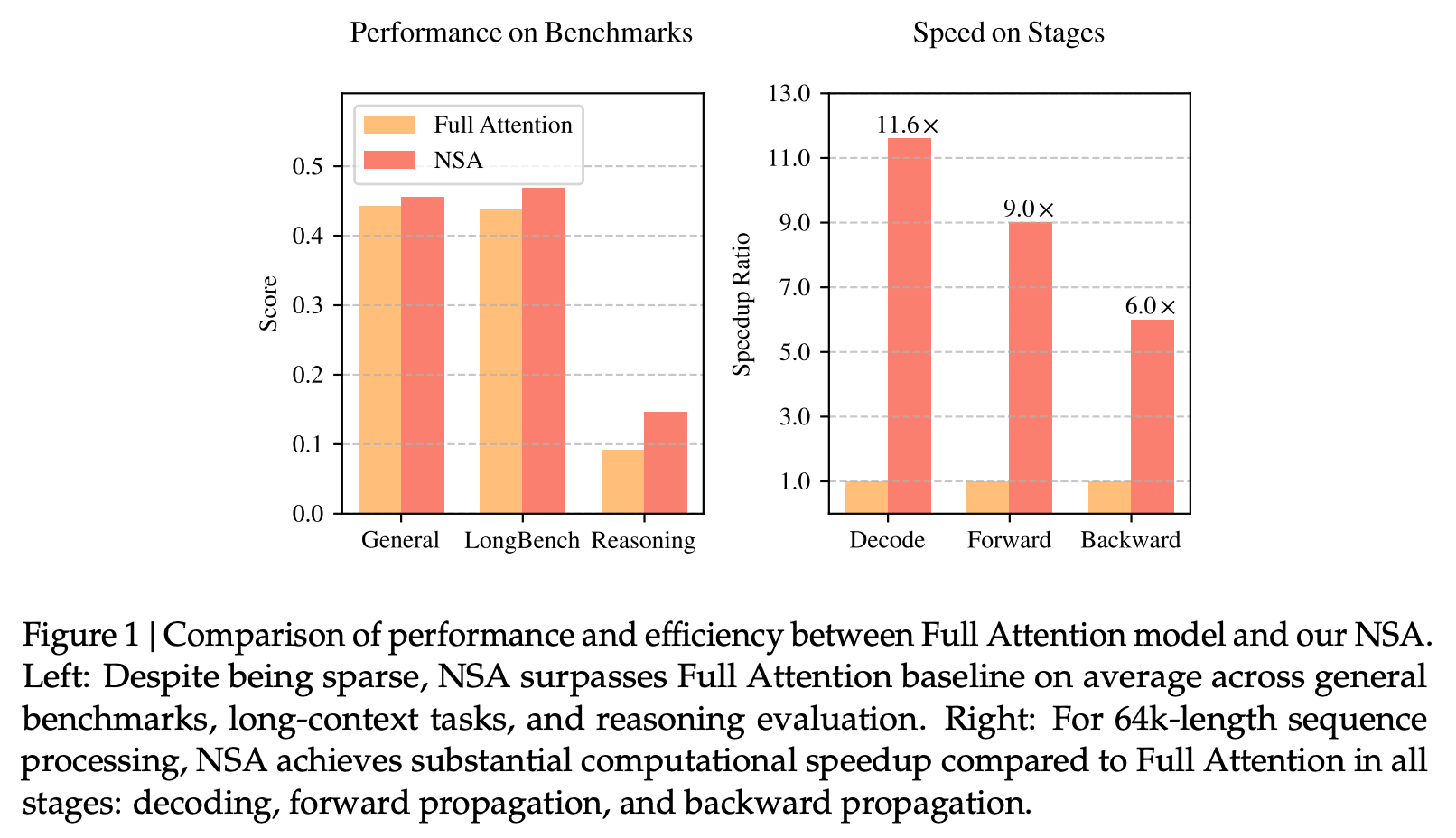
图片来源:DeepSeek的X账号
在DeepSeek发论文的同一天,月之暗面也发布了新论文,提出MoBA方法。该方法在1M token测试中比全注意力快了6.5倍,到10M token时提速16倍,已在Kimi产品中使用。
DeepSeek的新方法背后有三大技术:压缩、选择和滑动窗口。这些方法使NSA速度更快,同时保持与传统方法相当或更好的理解能力。有网友称,这是在教会AI学会“聪明的偷懒”,像人类一样聪明地分配注意力。
DeepSeek此次还对现有计算机硬件进行了优化,使用Triton框架而非英伟达专用库,为未来的开源和广泛应用奠定了基础。
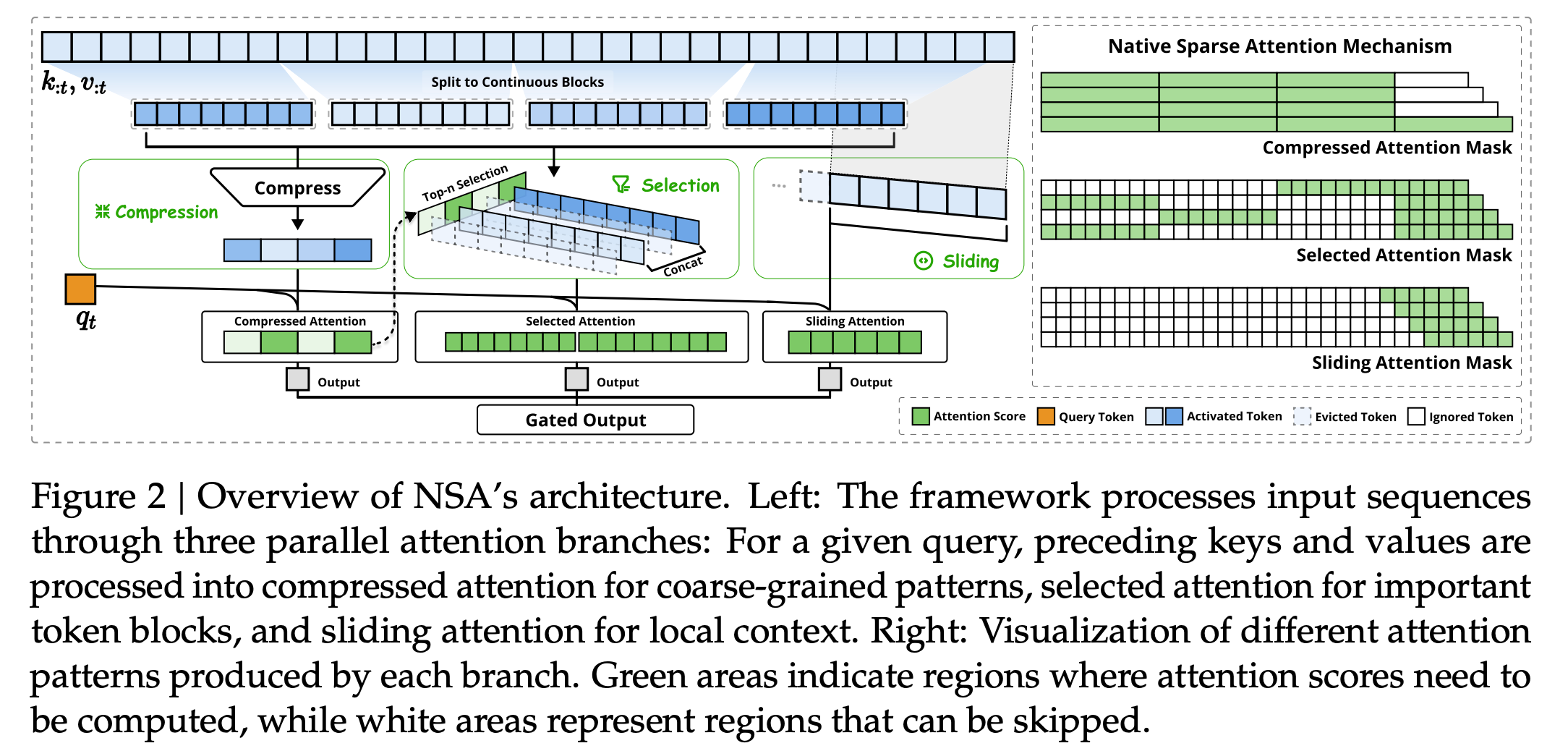
图片来源:DeepSeek
(文章来源:每日经济新闻)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。





