

DeepSeek发布NSA技术论文,引领AI迭代浪潮
AI导读:
DeepSeek发布关于NSA机制的纯技术论文报告,旨在解决长上下文建模的关键瓶颈。同时,多家公司开源AI模型,推动AI技术迭代,提高AI渗透率。
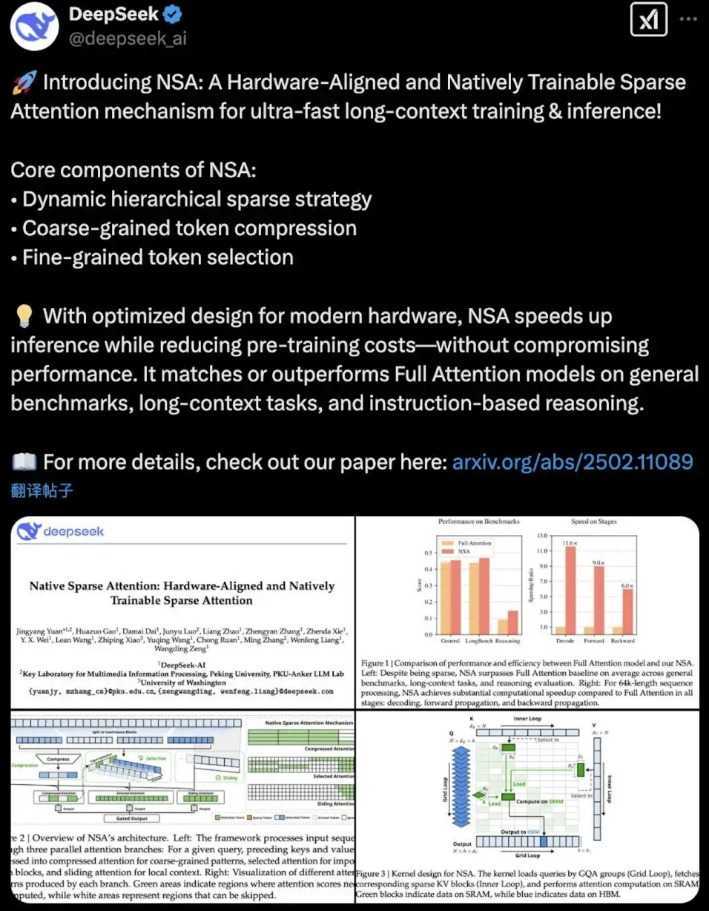
2月18日,Deepseek在海外社交平台发布了一篇纯技术论文报告,论文聚焦NSA(Natively Sparse Attention,原生稀疏注意力)机制。这是一种专为超快速长文本训练与推理设计的、硬件对齐且可原生训练的稀疏注意力机制,旨在解决长上下文建模的关键瓶颈。
同时,DeepSeek创始人梁文锋也作为共创者参与了这篇《原生稀疏注意力:硬件对齐且可原生训练的稀疏注意力机制》的论文撰写。
DeepSeek发布NSA技术论文报告
据论文摘要,DeepSeek团队指出,长上下文建模对下一代大型语言模型至关重要。然而,标准注意力机制在处理长序列时面临高复杂度问题,导致延迟瓶颈。NSA机制通过高效处理长序列,扩展了大语言模型在文档分析、代码生成等领域的应用。

NSA还针对现代硬件进行优化,提高推理速度,降低预训练成本,同时保持卓越性能。在通用基准测试、长文本任务中均表现出色。DeepSeek的NSA为AI领域提高效率、保持模型能力提供了新方向。
网友评论称:“DeepSeek的NSA架构新颖,但实际应用需考虑场景和硬件优化。”
“开源”引领AI迭代浪潮
近期,DeepSeek推出DeepSeek-R1模型后备受关注。同时,阶跃星辰也开源了两款多模态大模型,旨在推动AGI实现,为全球开源社区贡献力量。
围绕开源生态,商汤科技即将推出LazyLLM框架,支持开发者快速迭代数据,实现想法产品落地。MiniMax也持续开源高水平模型,加快优化“线性注意力”机制,打造多模态模型。
随着AI技术不断迭代,商业化最终落脚点在于客户价值。高水平模型的持续开源,将提高AI渗透率,让更多开发者参与打造非Transformer架构的底层生态。
(文章来源:上海证券报)

郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。










