DeepSeek爆火:私募基金跨界AI,中国大模型跻身全球前列
AI导读:
DeepSeek,一家成立仅1年半的AI创业公司,凭借新发布的推理大模型DeepSeek-R1成功登顶苹果美区应用商店免费App下载排行榜。其创新的技术路线和低廉的定价策略,让DeepSeek成为了AI界的黑马,也为中国大模型在全球竞争中弯道超车提供了可能。
1月26日至27日,国内AI创业公司DeepSeek(深度求索)在短短两天内遭遇了两次短暂宕机,公司归因于新发布的推理大模型DeepSeek-R1引发的访问量激增。
新模型DeepSeek-R1的发布带来了前所未有的访问热潮。据统计,27日,DeepSeek在苹果美区应用商店的下载量超越了ChatGPT,成功登顶免费App下载排行榜。这家原本默默无闻的创业公司,在短短一年多时间内,已成为大模型行业的“黑马”,引发了业界对国内大模型能否实现弯道超车的广泛讨论。
DeepSeek:好用且经济实惠的选择
早在2024年12月,DeepSeek发布的新一代大语言模型V3就已在行业内引起了广泛讨论,但1月20日发布的R1更是将DeepSeek推向了新的高度。国外大模型排名榜单Arena的最新测评显示,R1在基准测试中全类别大模型中排名第三,在风格控制分类中与OpenAI o1并列第一,竞技场得分高达1357分,甚至略胜一筹。这也意味着DeepSeek-R1已成功跻身全球最强大模型之列。
DeepSeek的官方测试也进一步证实了R1的实力。在数学、代码、自然语言推理等任务上,R1的性能与OpenAI o1正式版不相上下。在小参数版本的模型比拼中,R1-32B与o1-mini各有千秋,其中R1-32B在数学推理方面表现尤为出色。
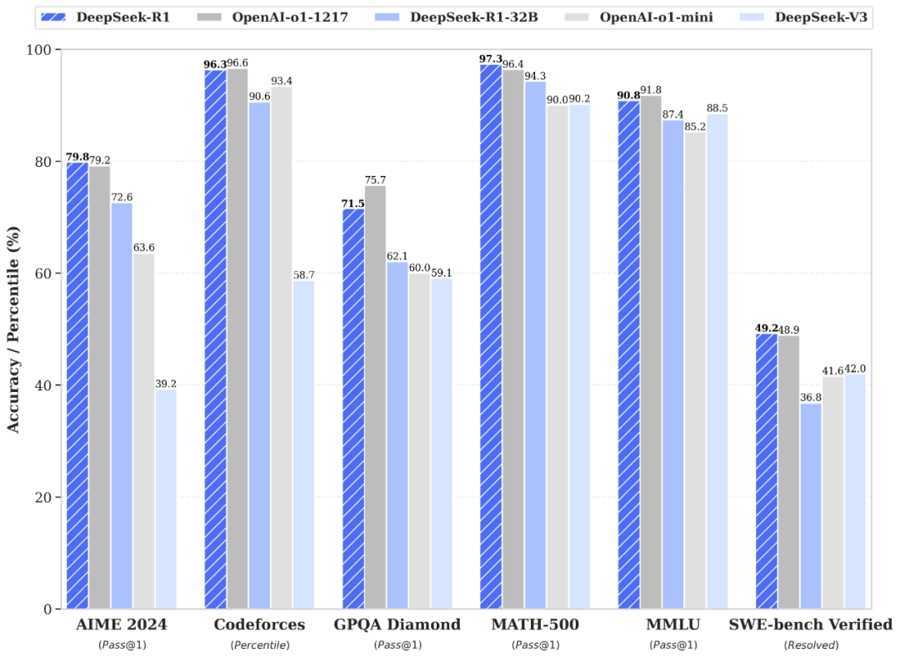
DeepSeek-R1性能与OpenAI-o1比肩。
DeepSeek的横空出世,令硅谷多位AI大佬刮目相看。无论是微软CEO还是OpenAI的投资人,都公开称赞DeepSeek-R1作为开源模型在推理计算能力上的出色表现。而《黑神话:悟空》的主创成员冯骥在使用R1后,更是指出了其六大优势:强大、便宜、开源、免费、联网和本土。特别是便宜、免费、联网等优势,让DeepSeek全面超越了OpenAI、Meta、Google等AI巨头。
DeepSeek的定价策略确实极具竞争力。推理模型R1的API服务定价为每百万tokens(词元)仅需1元(缓存命中)/4元(缓存未命中),每百万输出tokens为16元。而大语言模型V3的定价更为亲民,每百万tokens仅需0.1元(缓存命中)/1元(缓存未命中),每百万输出tokens为2元。这一定价策略约等于Llama 3-70B的七分之一,GPT-4 Turbo的七十分之一。
回顾2024年5月,国内大模型掀起了一股降价潮,不少大模型的API价格下调90%以上。而DeepSeek作为首家降价的大模型,被誉为AI界的“拼多多”。
展现本土技术创新的魅力
这样一款既便宜又好用的大模型,为何会诞生在一家成立仅1年半的创业公司?这不得不提DeepSeek与生俱来的算力优势和技术优势。
天眼查信息显示,DeepSeek背后的实控人是梁文锋,他所创立的幻方量化是国内知名的量化私募基金。这为DeepSeek提供了坚实的算力基础。不同于常规基金依赖基金经理,量化基金通过数量模型的计算寻找投资机会,对数据尤为敏感,其高频交易的特点更是离不开机器学习。为了从海量数据中挖掘投资机会,幻方量化早早开始囤积算力,先后斥资10亿元,在美国对芯片出口管制前购买了1万张英伟达A100型号GPU。机缘巧合下,幻方量化成为国内GPU算力最充足的企业之一。

DeepSeek成功登顶App Store美区榜首。
在AI行业中,有一条Scaling Law(规模化法则),即大模型的性能与其训练资源、数据集和参数规模存在正相关性。算力越大、参数越多,训练出的大模型性能就越好。幻方量化的算力基础,无疑成为了DeepSeek最大的王牌之一。
然而,光靠算力优势,DeepSeek显然无法与全球AI巨头抗衡。上海人工智能行业协会秘书长钟俊浩认为,DeepSeek之所以爆火,主要是因为其创新的技术路线。架构机制、训练方法和管道并行算法等创新,展现了中国本土AI技术的潜力,颠覆了中国只是AI技术跟随者、应用方的传统认知。
据DeepSeek公布的技术论文显示,R1在训练过程中实验了三种技术路径:直接强化学习、多阶段渐进训练和模型蒸馏。其中,R1首次证明了直接强化学习的有效性。科技媒体在技术解读中打了个比方:面对同一道题目,大模型同时多次进行回答,系统将给每个答案打分,依照“高分奖励低分惩罚”的逻辑进行循环,最终得出更具优势的推理路径。
与此同时,DeepSeek还采用了混合专家模型(MoE)创新架构,只需激活5%—10%的专家网络,就大幅降低了大模型训练的算力要求。同时,还采取了FP8混合精度训练,减少了模型训练的显存占用量。
本着“该省省该花花”的训练思路,DeepSeek最新大语言模型V3的训练成本仅为558万美元,不足GPT-4o的二十分之一。
展望未来:国内大模型的弯道超车机会
随着OpenAI o1、豆包、通义等推理大模型的陆续发布,DeepSeek-R1的加入无疑将这场推理竞赛推向了白热化。钟俊浩认为,人工智能技术的发展具有其内在逻辑,主要体现在实现从“记忆”到“思考”的跨越,一定程度上解决逻辑上的“幻觉”问题。
早期大模型的核心能力是海量知识的压缩存储与模式匹配,就像是“填鸭式”教育,把大量的知识都背出来。这种“死记硬背”的模式虽然能快速给出答案,但也存在问题,比如缺乏深度思考、甄别判断能力,容易人云亦云。而推理能力需要模型具备动态规划、因果推断和符号逻辑处理能力。OpenAI的o1通过改进架构和训练方法,使模型逐步从“鹦鹉学舌”转向“解题专家”。
在长文本交互和多模态的全球竞争中,国内大模型已经崭露头角。随着大模型推理能力的迭代,中国还有机会实现弯道超车。钟俊浩认为,高效利用计算资源、相对较低的成本以及更高的市场活跃度,是国内训练推理大模型的优势所在。
“推理模式所需的处理数据量相对较小,对高性能集成电路算力芯片的需求强度相对减少。”他表示,虽然国内面临高端算力芯片紧缺的难题,但推理大模型能更集约利用有限的算力资源。同时,国内算力基础设施较为完备,训练硬件成本较低。
更重要的是,中国的人工智能市场处于开放竞争的状态。不仅有阿里、字节、商汤等大型AI厂商,还有阶跃星辰、MiniMax等高水平的AI创业企业。而美国则主要集中在微软、谷歌等巨头。更多的市场参与者意味着更多的创新想法,也意味着市场更活跃。
此外,中国具有极强的政策引导能力。以上海发布的“模塑申城”实施方案为例,该方案进一步明确了“5+6”应用场景,为人工智能企业在推理方面的应用拓宽了发展空间,从而引导市场形成,加速商业化进程。
(文章来源:上观新闻)

郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。










