上海AI实验室发布“万卷·丝路”多语言语料库
AI导读:
上海AI实验室发布“万卷·丝路”多语言预训练语料库,涵盖泰、俄、阿、韩、越等五个语种,总规模超1.2TB,旨在为多语言大模型训练提供高质量数据支撑,推动人工智能技术在共建“一带一路”中发挥更关键作用。
随着共建“一带一路”进入高质量发展新阶段,科技创新与合作在其中扮演着日益重要的角色。上海人工智能实验室(上海AI实验室)通过研发前沿的数据智能技术,并提供多语言语料库等创新举措,积极探索人工智能在高质量共建“一带一路”中的赋能作用。
1月9日,上海AI实验室携手大模型语料数据联盟成员,共同发布了名为“万卷·丝路”的多语言预训练语料库。这一语料库旨在为多语言大模型的训练提供坚实的数据支撑,推动人工智能技术的进一步发展。
“万卷·丝路”语料库在首期即开源了泰语、俄语、阿拉伯语、韩语和越南语五个语种的语料,总规模超过1.2TB(每个单语种的数据量均超过150GB),Token总数更是达到了300B(300 billion)之巨。这些语料涵盖了使用上述语种国家地区的生活、百科、文化、新闻等七大领域的数据,为研究者提供了丰富多样的研究素材。
数据作为人工智能的重要基础设施,其质量直接决定了人工智能应用的能力。针对当前多语言语料库发展不平衡、高质量语料短缺的现状,上海AI实验室通过开源“万卷·丝路”语料库,为业界提供了有力支持。该语料库采集了多个国家地区的网络公开信息、文献、专利等资料,数据总规模庞大,处于国际领先水平。
为了满足多样化研究需求,“万卷·丝路”语料库基于“书生·浦语”智能标签分类体系,将每个语料子集细分为7个大类和32个小类。这些类别涵盖了历史、政治、文化、房产、购物、天气、餐饮、百科、专业知识等多个领域,便于研究者根据具体需求快速检索数据。

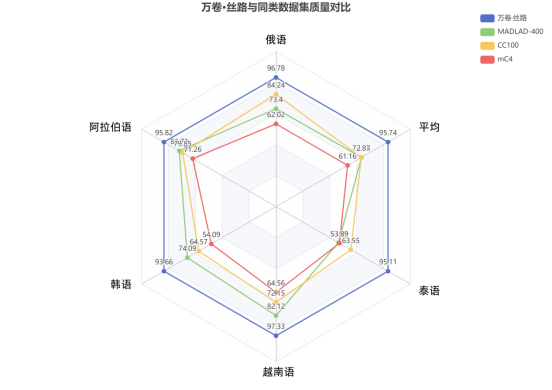
此外,“万卷·丝路”语料库还通过专家人工标注和数据智能相结合的方式,确保了数据的高标准与高质量。研究团队利用基于大语言模型的数据质量评估开源工具Dingo,从完整性、有效性、可理解性、流畅性、相关性、相似性和安全性等多个维度对语料库的数据质量进行了全面评估。结果显示,五个子集均获得了优异的综合评分,显著优于同类语言语料库。
为了全面提升数据质量与适用性,上海AI实验室研究团队为“万卷·丝路”设计了一套精准化数据处理流程。该流程包括标准化处理数据、高效去重、建立域名黑名单筛除不良网页数据、构建多语言特色敏感词表并结合语境评估精准过滤有害内容、训练语言安全模型进行多维度不良内容检测和筛选、利用主题分类器优化知识域分布以及通过PPL(困惑度)初筛和基于BERT的质量分类模型精准筛选高质量内容等多个步骤。这一流程有效融合了多语言特点与行业通识技术,为多语言模型训练提供了高质量、安全可靠的数据基础。

实验结果显示,使用“万卷·丝路”数据集后,模型在多语言内容理解及推理能力上的表现均获得了显著提升。这一成果进一步验证了“万卷·丝路”语料库在推动人工智能技术发展方面的重要作用。
值得一提的是,大模型语料数据联盟由上海人工智能实验室联合中央广播电视总台、人民网、国家气象中心、中国科学技术信息研究所、上海报业集团、上海文广集团等10家单位共同发起。该联盟旨在通过链接模型训练、数据供给、学术研究、第三方服务等多方面机构,联合打造多知识、多模态、标准化的高质量语料数据,并探索形成基于贡献、可持续运行的激励机制,以打造国际化、开放型的大模型语料数据生态圈。
(文章来源:科创板日报,有删改)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。




