DeepSeek-V3震撼发布:AI技术新突破,性价比全球领先
AI导读:
DeepSeek发布最新AI大模型DeepSeek-V3并同步开源,成本远低于国际顶尖模型,排名全球前十,性价比最高,在复杂问题和代码领域表现优异,技术路线备受关注。
2024年12月26日,人工智能企业深度求索(Deepseek)震撼发布其最新AI大模型DeepSeek-V3,并宣布同步开源,此举迅速在中外AI领域引起轰动。DeepSeek在短短两年内,以557万美元的成本成功研发出与国际顶尖AI模型比肩的DeepSeek-V3,与OpenAI耗资7800万美元训练的GPT-4形成鲜明对比。
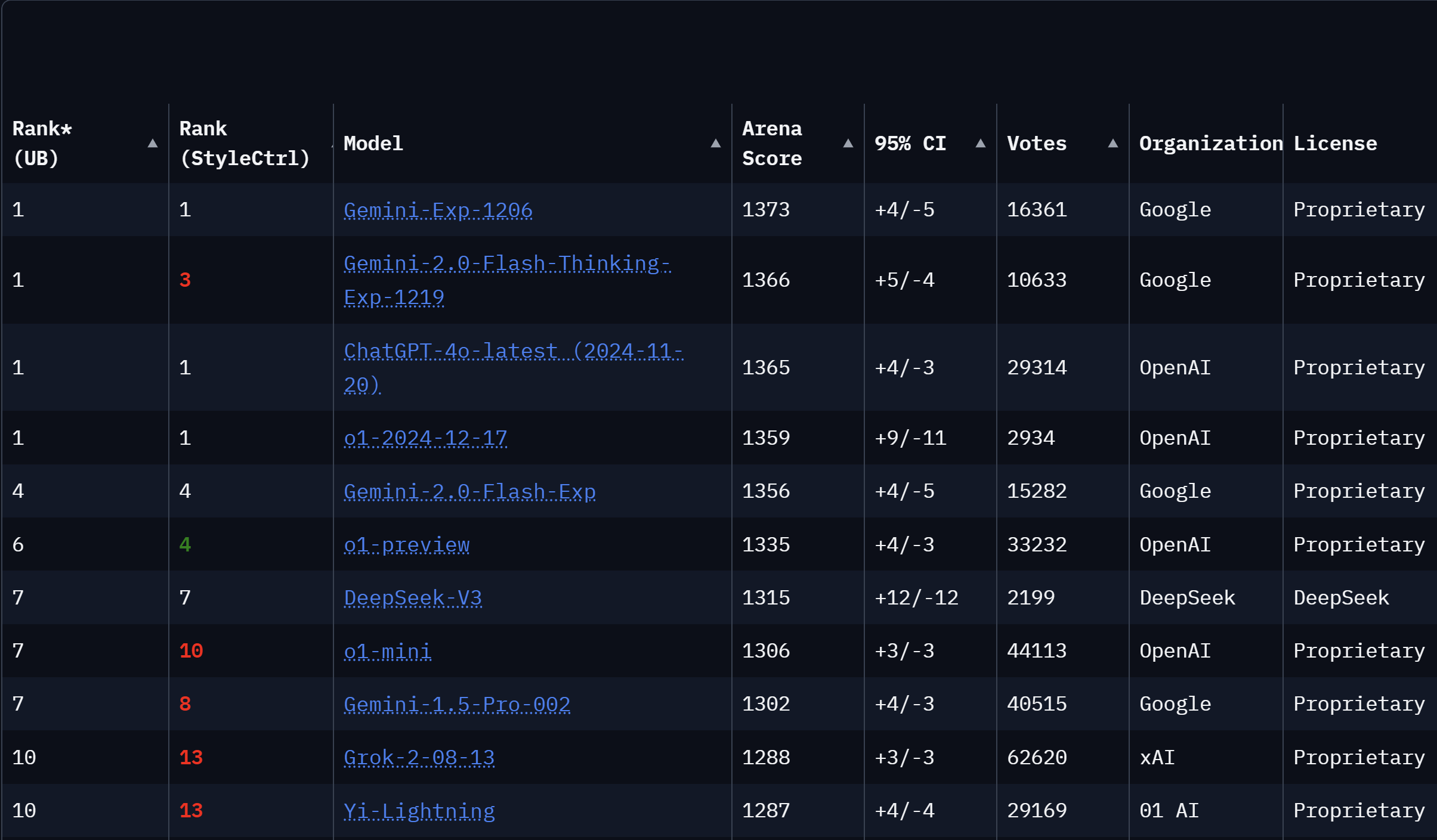
据聊天机器人竞技场(Chatbot Arena)最新数据显示,DeepSeek-V3在全球大模型排名中位列第七,更在开源模型中独占鳌头。竞技场官方高度评价DeepSeek-V3为全球前十中性价比最高的模型,其在风格控制下表现稳健,且在复杂问题和代码领域的表现均跻身前三。
DeepSeek通过长达55页的技术报告,向公众全面展示了其技术路线。虽然有人对DeepSeek-V3的技术突破表示质疑,认为其只是现有优化技术的集成,但业内人士指出,DeepSeek-V3是首个创新融合FP8、MLA、MoE三项技术的大模型,这一融合被视为实质性的技术突破。
聊天机器人竞技场的数据显示,DeepSeek-V3不仅排名第七,更成为前十名中唯一的开源国产模型,被誉为国产第一。DeepSeek-V3在风格控制下表现稳健,且在复杂问题和代码领域的排名冲进前三。
聊天机器人竞技场采用Elo评分系统,通过用户投票反映真人用户对于大模型的偏好,是目前最知名的大模型评比榜单。AI智能体与大语言模型集成平台Composio也从多个维度对DeepSeek-V3与目前最流行的两个大模型进行了比较,结果显示DeepSeek-V3在推理、数学方面表现优异,编程方面接近GPT-4o,创意写作方面与GPT-4o相差不大。
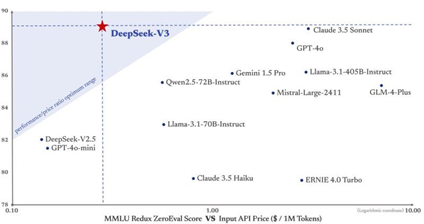
尤为值得一提的是,DeepSeek-V3的API输入价格仅为每百万Token 0.1元人民币,远低于其他模型。考虑到性价比,Composio认为DeepSeek-V3是构建面向客户的AI应用程序的理想选择。
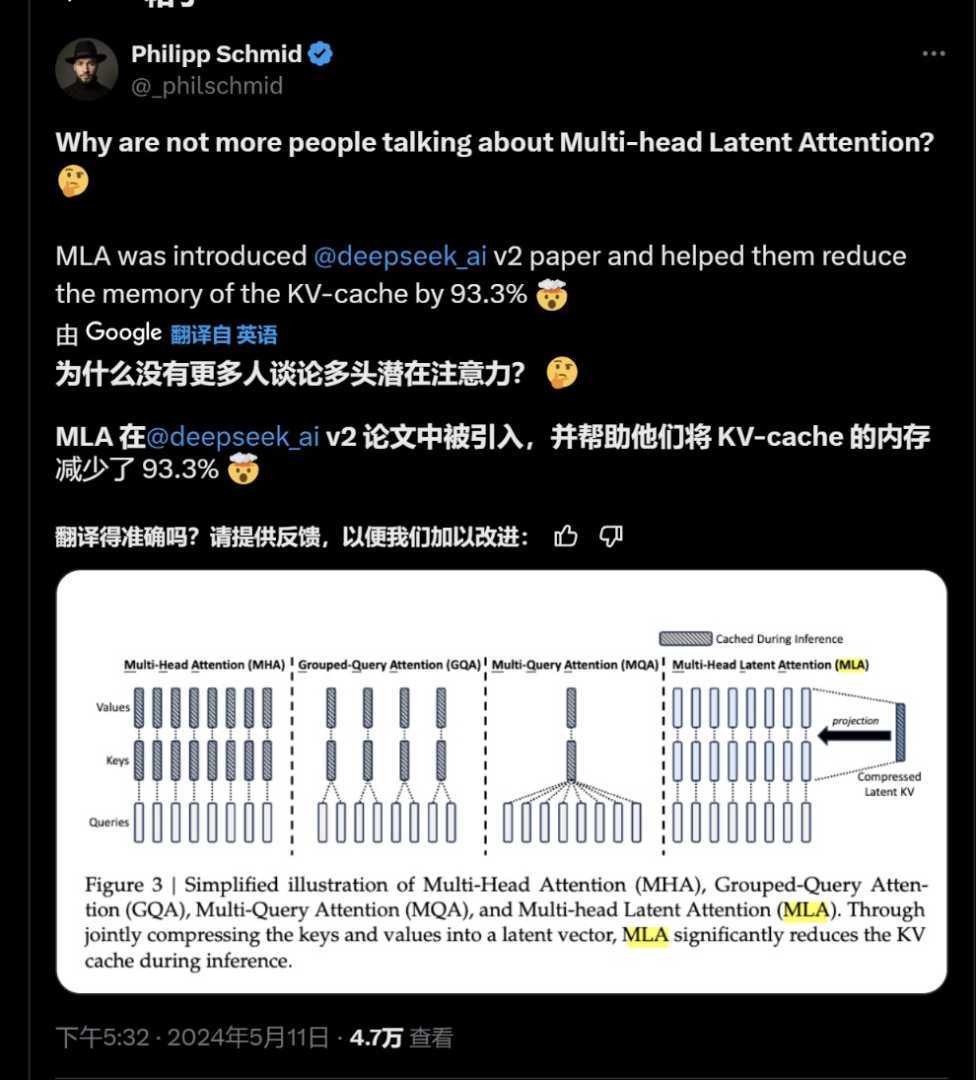
面对关于技术集成的质疑,DeepSeek在长达55页的技术报告中详细解释了其技术路线。DeepSeek-V3利用混合专家(MoE)架构优化性能,同时融合使用多头潜在注意力(MLA)、FP8混合精度等技术,进一步提高了效率和有效性。资深业内人士猫头虎表示,DeepSeek-V3作为首个综合实力匹敌Meta的Llama3.1-405B的国产开源大模型,创新性地同时使用了FP8、MLA和MoE三种技术手段。
FP8是一种新的数值表示方式,用于深度学习的计算加速。DeepSeek-V3是全球首家在超大规模模型上验证FP8有效性的模型,这一技术至少将显存消耗降低了30%。此外,DeepSeek-V3使用的MoE模型更为精简有效,通过创新策略实现了更高的专家专业化和性能。而MLA机制则完全由DeepSeek团队自主提出,并最早作为核心机制引入了DeepSeek-V2模型上,极大地降低了缓存使用。
FP8、MLA和MoE的融合,是AI技术向更高效率、更低成本发展的典型案例。在DeepSeek-V3的推动下,这些技术展现出了广阔的应用前景。
图片来源:聊天机器人竞技场
图片来源:X

图片来源:arXiv

图片来源:arXiv
图片来源:X
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。




