幻方量化发布DeepSeek-V3,性能大幅提升但价格翻倍
AI导读:
幻方量化发布全新AI模型DeepSeek-V3,性能大幅提升,生成速度达每秒60 token,完全开源,应用场景广泛,但API服务定价上调2倍有余。
12月26日晚,量化投资机构幻方量化宣布,全新模型Deepseek-V3正式上线并同步开源,其API服务也同步更新,无需改动接口配置。这一消息标志着幻方量化在AI技术上的又一重大突破。
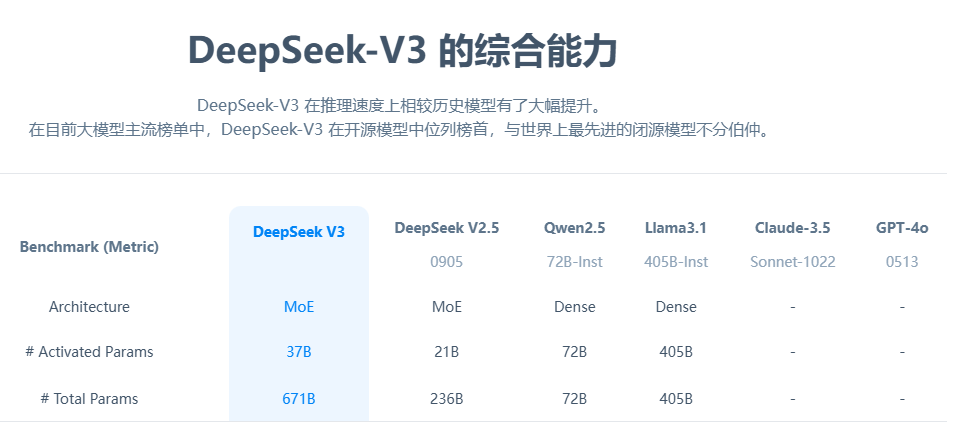
DeepSeek-V3作为幻方量化的自研MoE模型(Mixture of Experts,混合专家模型),相较于9月6日正式发布的上一代模型DeepSeek-V2.5,在生成速度上实现了3倍的提升,尽管目前暂不支持多模态输入输出。DeepSeek-V3拥有6710亿参数,其中激活参数为370亿,在14.8万亿token上进行了预训练。
具体而言,DeepSeek-V3的生成速度高达每秒60 token,相比V2.5版本有了显著提升。同时,该模型完全开源,为开发者提供了更多可能性。在多语言处理方面,尽管当前版本不支持多模态输入输出,但在算法代码和数学方面表现出色。
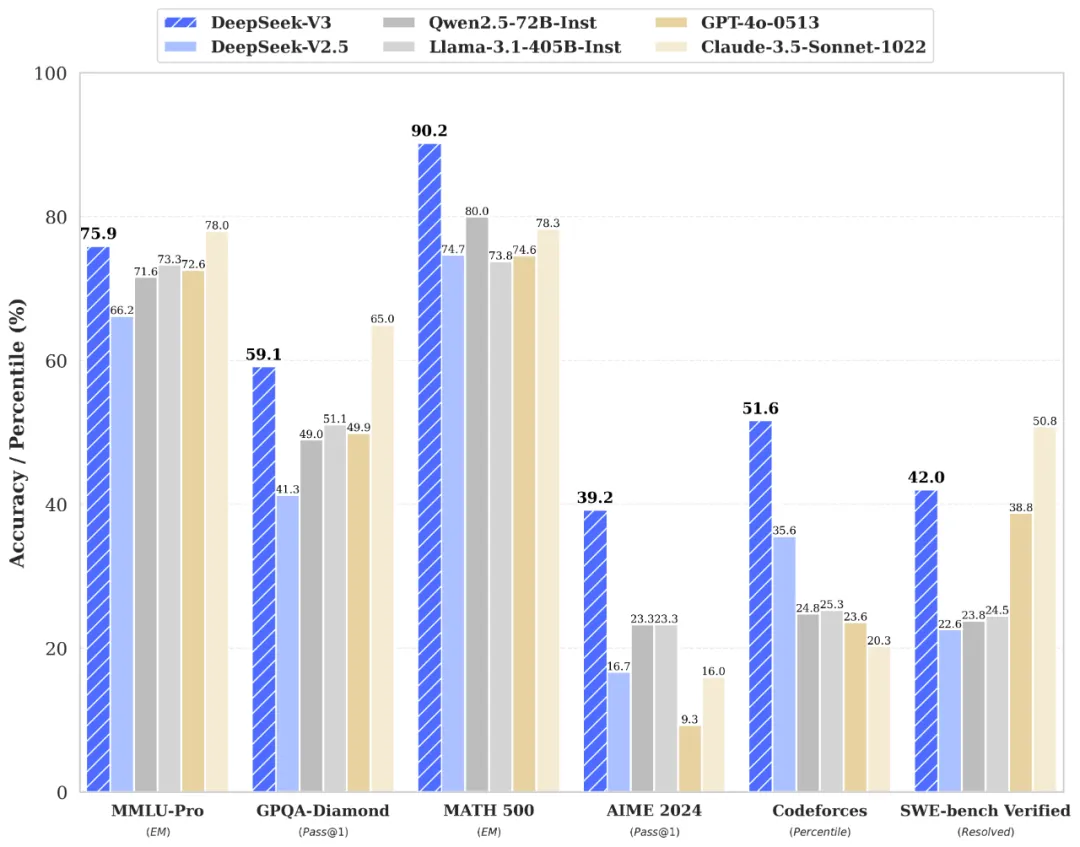
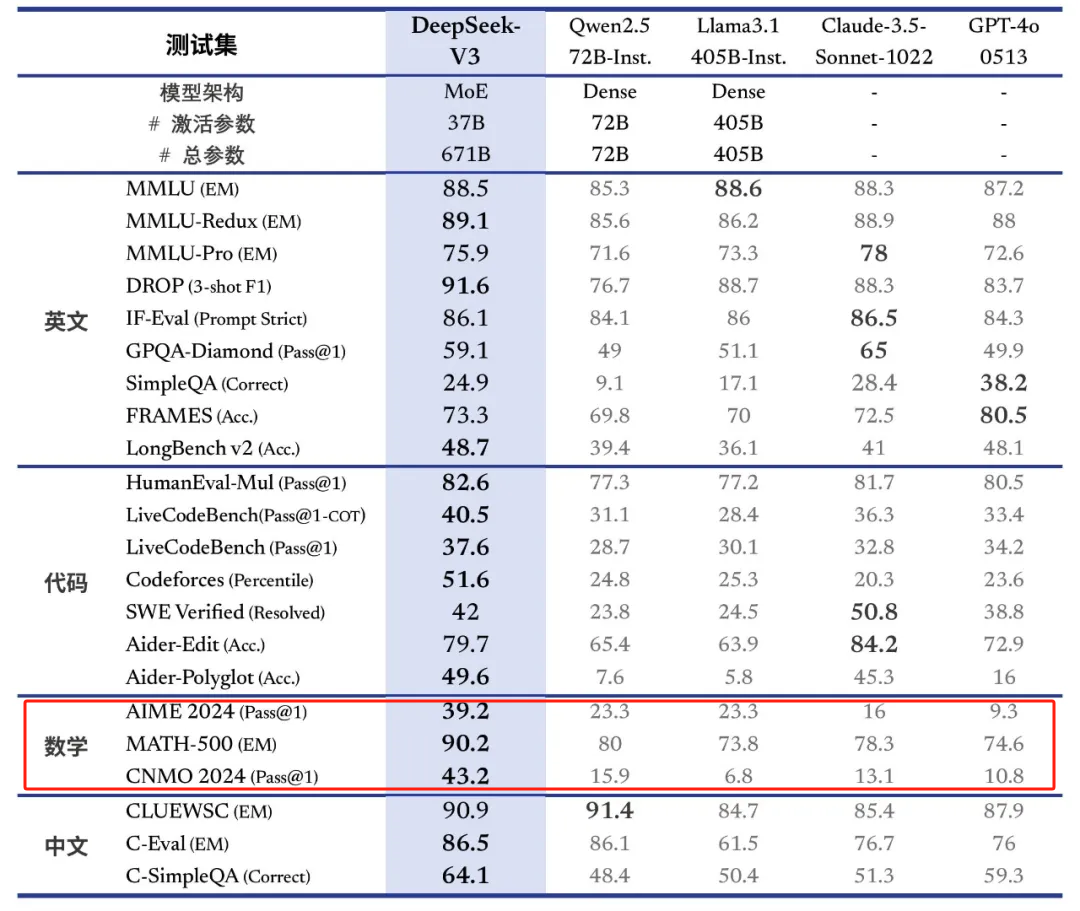
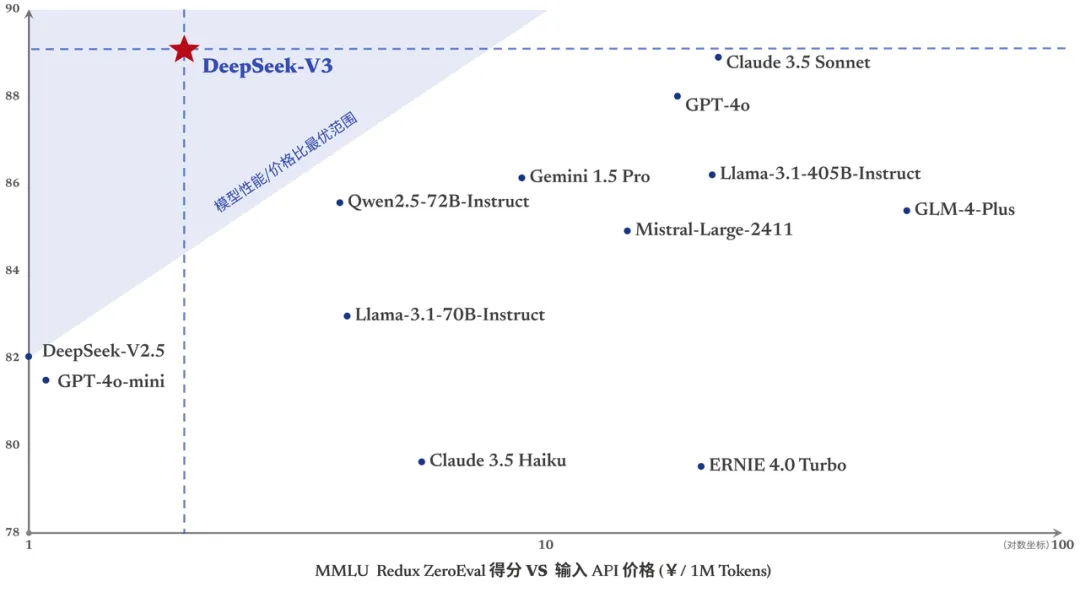
DeepSeek-V3在多项基准测试中表现优异,成绩超越了Qwen2.5-72 B和Llama-3.1-405 B等其他开源模型,与世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet在性能上不分伯仲。尤其在数学能力方面,DeepSeek-V3大幅超过了所有开源和闭源模型。
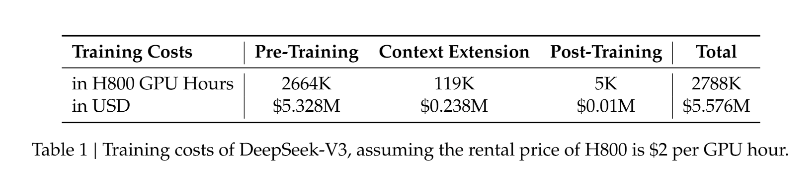
值得注意的是,幻方量化在已开源的论文中强调其训练成本极低。通过算法、框架和硬件的优化协同设计,假设H800GPU的租用价格为每块GPU2美元/小时,DeepSeek-V3的全部训练成本总计仅为557.6万美元。在预训练阶段,模型每训练1万亿token仅需要180K个GPU小时,即在配备2048个GPU的集群上只需3.7天,团队使用2048块H800 GPU训练了模型不到2个月便达成目标。
技术大牛Andrej Karpathy发文称赞道,要达到DeepSeek-V3这种级别的能力,通常需要约1.6万个GPU的计算集群,而DeepSeek-V3却只用了280万GPU小时(计算量减少了约11倍)。Stability AI前CEO也表示,以每秒60个token的速度全天候运行DeepSeek-V3,每天仅需2美元。
DeepSeek-V3的发布将为开发者、企业和研究人员提供强大的工具和资源,应用场景包括聊天和编码、多语言自动翻译、图像生成和AI绘画等。然而,值得注意的是,尽管DeepSeek-V3性能更强、速度更快,但其API服务定价也上调了2倍有余,为每百万输入tokens 0.5元(缓存命中)/2元(缓存未命中),每百万输出tokens 8元,按缓存未命中的输入价格计,加总成本是10元人民币。
尽管提价,但与同类型模型相比,DeepSeek-V3依旧极具性价比。比如OpenAI的GPT 4o定价相当高,加总成本是20美元,约合人民币140元。列夫·托尔斯泰的名著《战争与和平》的英文版,让DeepSeek-V3读完全文只需要2元左右。
(文章来源:财联社)

郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。











