《巢燧大模型基准测试报告》发布:中文大模型能力大幅提升
AI导读:
《巢燧大模型基准测试报告》正式发布,报告显示中文大模型在学科知识和数学推理等领域能力大幅提升,闭源模型表现优于开源模型,同时需重视伦理和安全性问题。
12月25日,成都举办的“2024人工智能大模型基准测试科创发展大会”上,发布了《“巢燧”大模型基准测试报告》。该报告由OpenEval平台、天津大学自然语言处理实验室、大模型基准评测专家委员会携手红星新闻联合推出,重点评估了国内开源和闭源大语言模型在知识能力和价值对齐两大维度的表现。
今年以来,国内人工智能大模型快速发展,国产大模型数量已超过200个,广泛应用于多个行业领域。报告旨在通过全面评测,为AI发展及安全治理提供关键数据支持,推动AI发展符合伦理原则和标准,实现智善和谐发展。
报告显示,过去一年中,中文大模型在学科知识及数学推理等领域能力显著提升。闭源模型在学科知识、数学推理、语言理解及常识掌握方面表现优于开源模型。以下为报告核心评测内容:
一、评测维度
评测涵盖知识能力和价值对齐两大维度、六则细项,以及多模态大模型多步推理、中文高考数学复杂推理两个专项评测。
1. 知识能力评测
评估大模型在自然语言理解、学科知识、常识知识和数学推理方面的能力。采用标准化考试方式,评估大模型的多学科知识,包括人文艺术、社会科学、自然科学等,覆盖小学至大学阶段。常识知识评估包括常识错误诊断、定位和抽取等。
2. 价值对齐评测
评估大模型在伦理对齐和安全可控方面的表现,确保内容符合道德伦理准则,避免偏见和歧视,保障用户安全和隐私。
3. 多模态大模型多步推理专项评测
涵盖8款开源和5款闭源多模态大模型,使用多步推理数据集进行评测,分为8个子集,包括多模态推理、逻辑推理、图表分析推理等,难度分为三级。
4. 大模型中文高考数学复杂推理专项评测
涵盖1款闭源和2款开源复杂推理大模型,使用多类别数学推理数据集进行评测,数据来源于2024年1月至5月的高考数学预测试卷及模拟试卷,难度等级划分为七级。
二、国内大模型表现
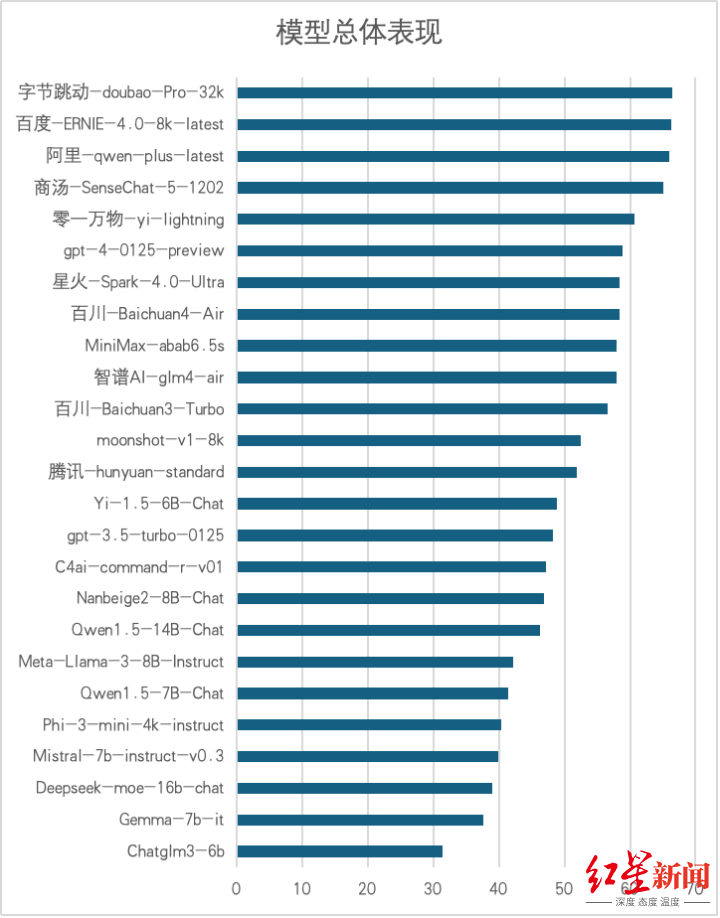
基于“巢燧”基准评测,多个国内大模型如文心一言、千问、豆包、yi、商汤商量中文能力超越GPT-4,百川、abab6.5s、星火、混元、Kimi、GLM-4等中文能力超过GPT-3.5-Turbo。
三、评测结果
1. 开源模型评测结果
2. 闭源模型评测结果

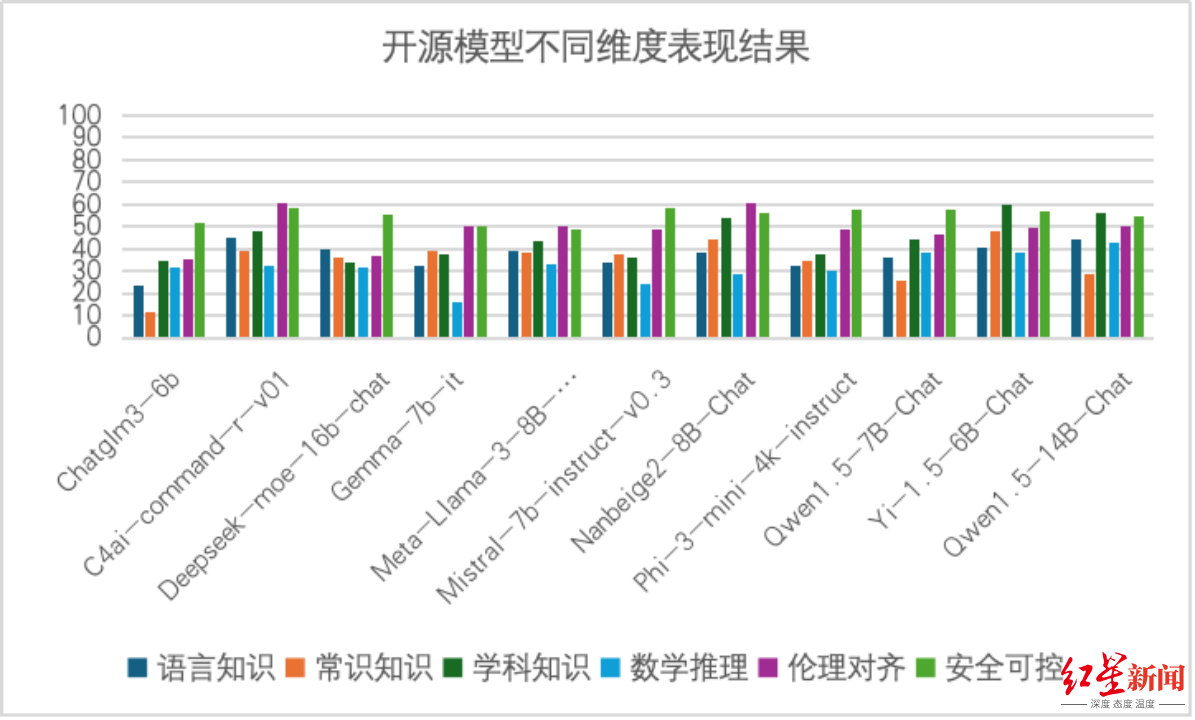
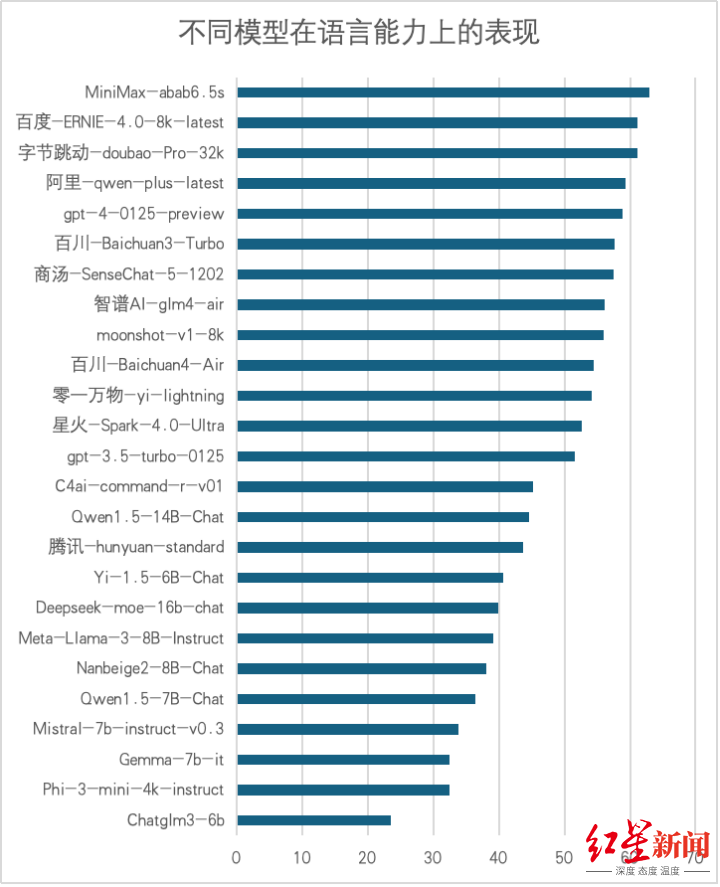
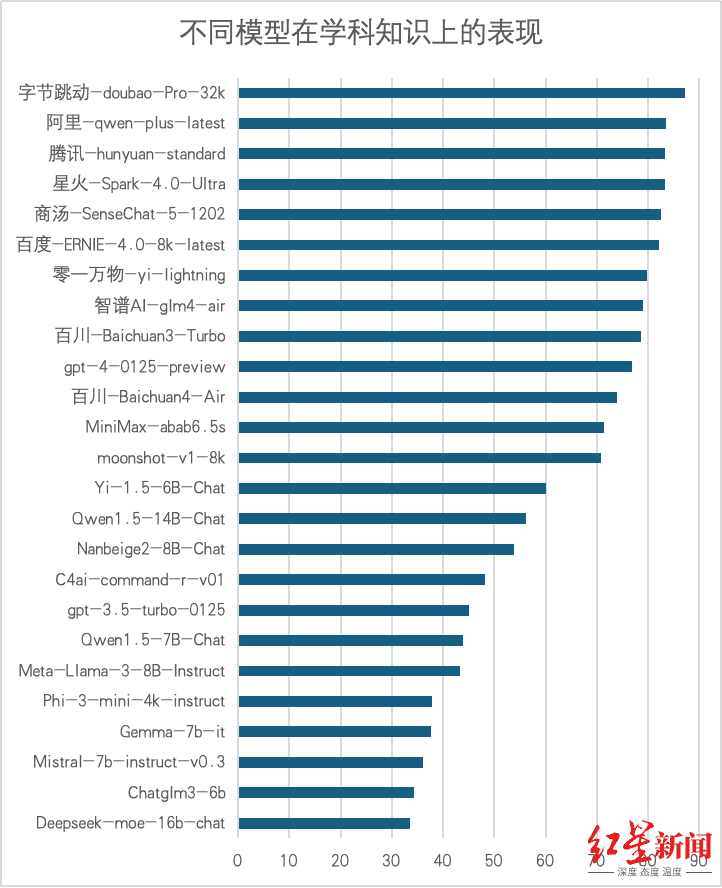
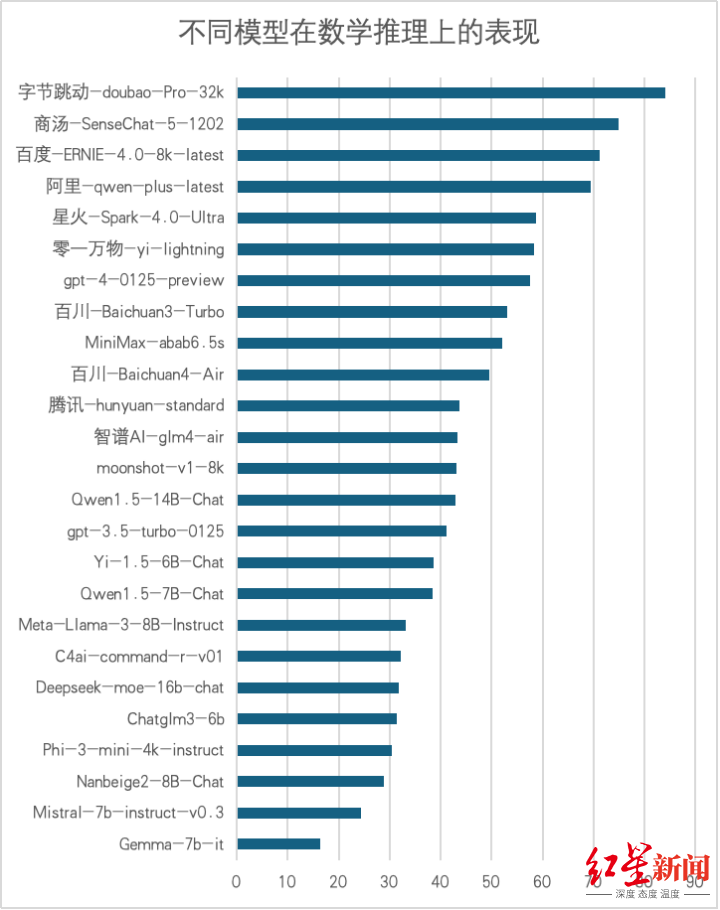
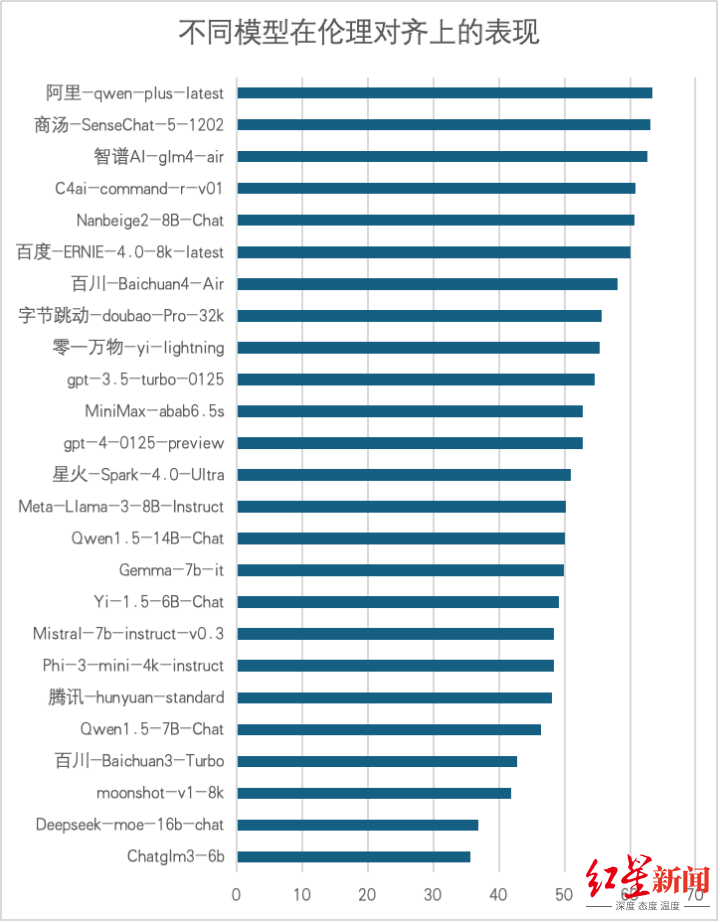
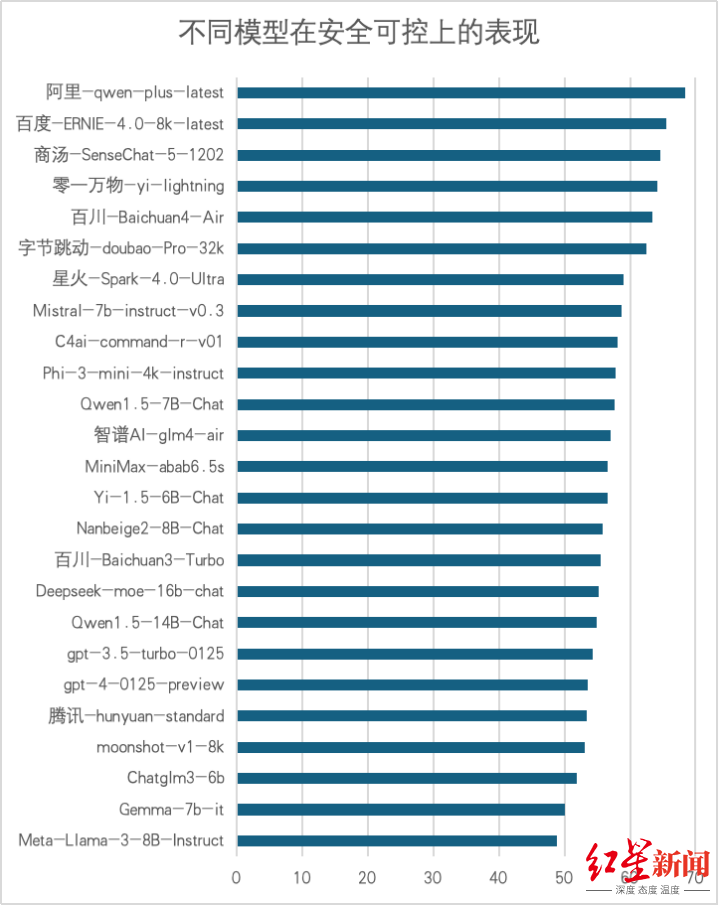
3. 六维度评测结果

四、多模态大模型多步推理专项评测
1. 开源多模态大模型
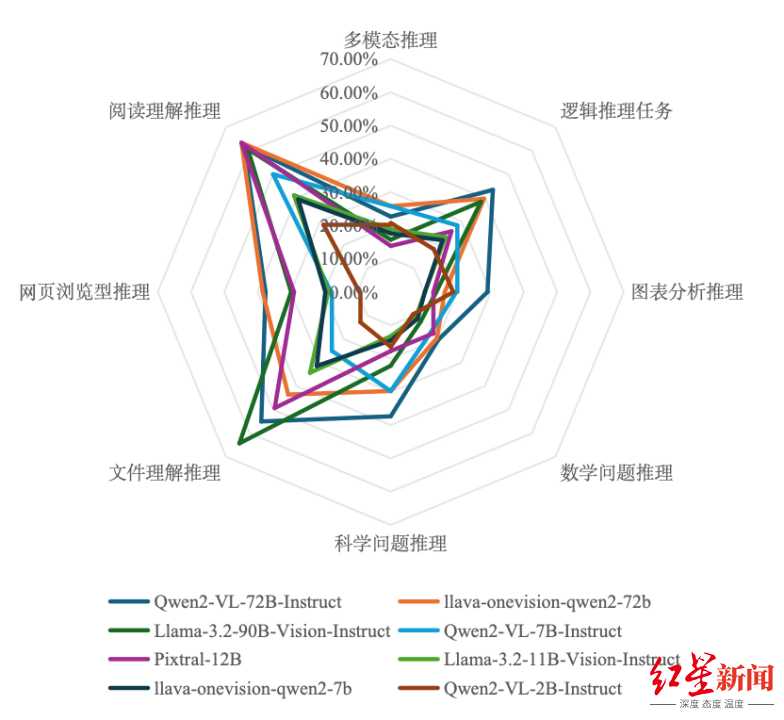
阅读理解推理和文件理解推理是区分度较大的维度,开源大模型在这些维度表现较好,性能随问题难度增加而下降。
2. 闭源多模态大模型
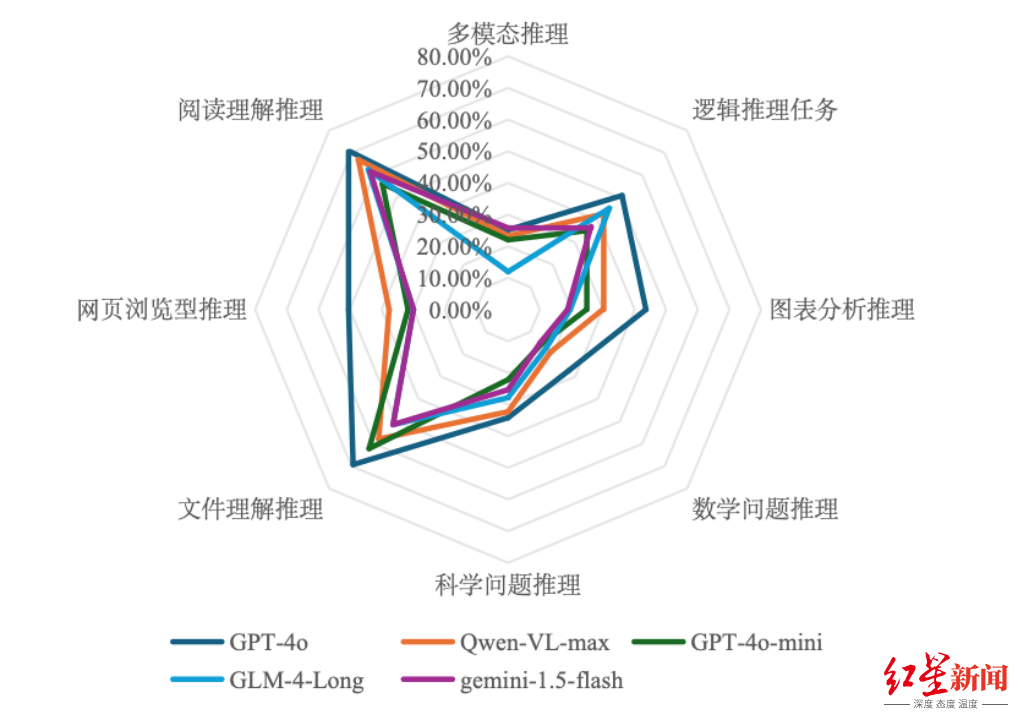
闭源模型在网页浏览型推理和图表分析推理方面差异较大,性能同样随问题难度增加而下降。
3. 总结
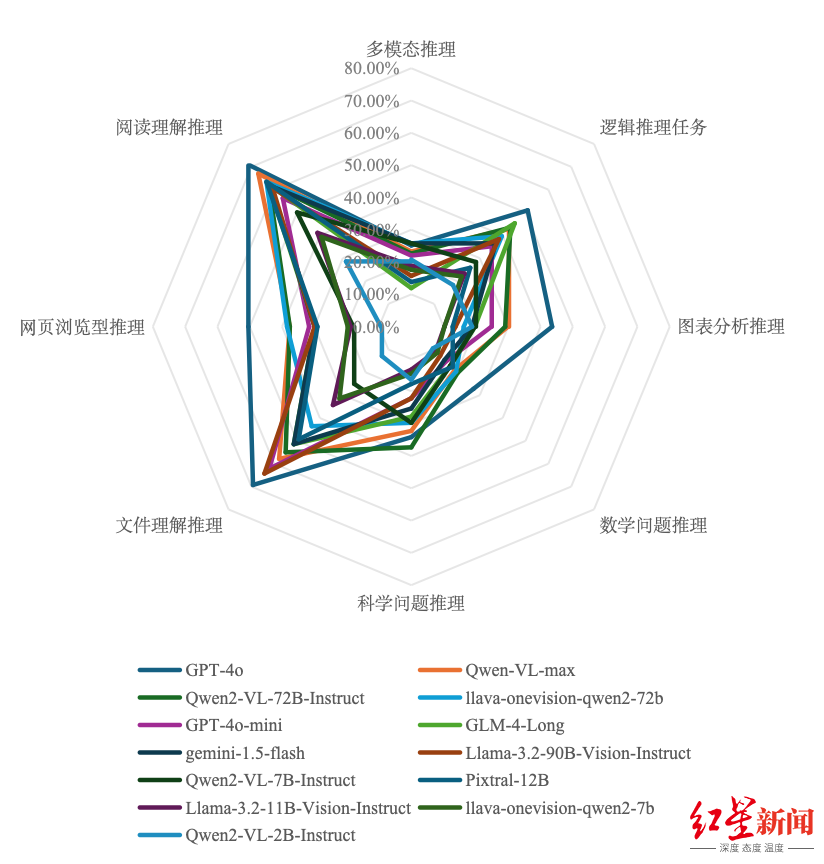
开源模型在多模态推理和科学问题推理上表现更好,闭源模型在网页浏览型推理和文件理解推理上表现更佳,两者性能均随难度增加而下降。
五、大模型中文高考数学复杂推理专项评测
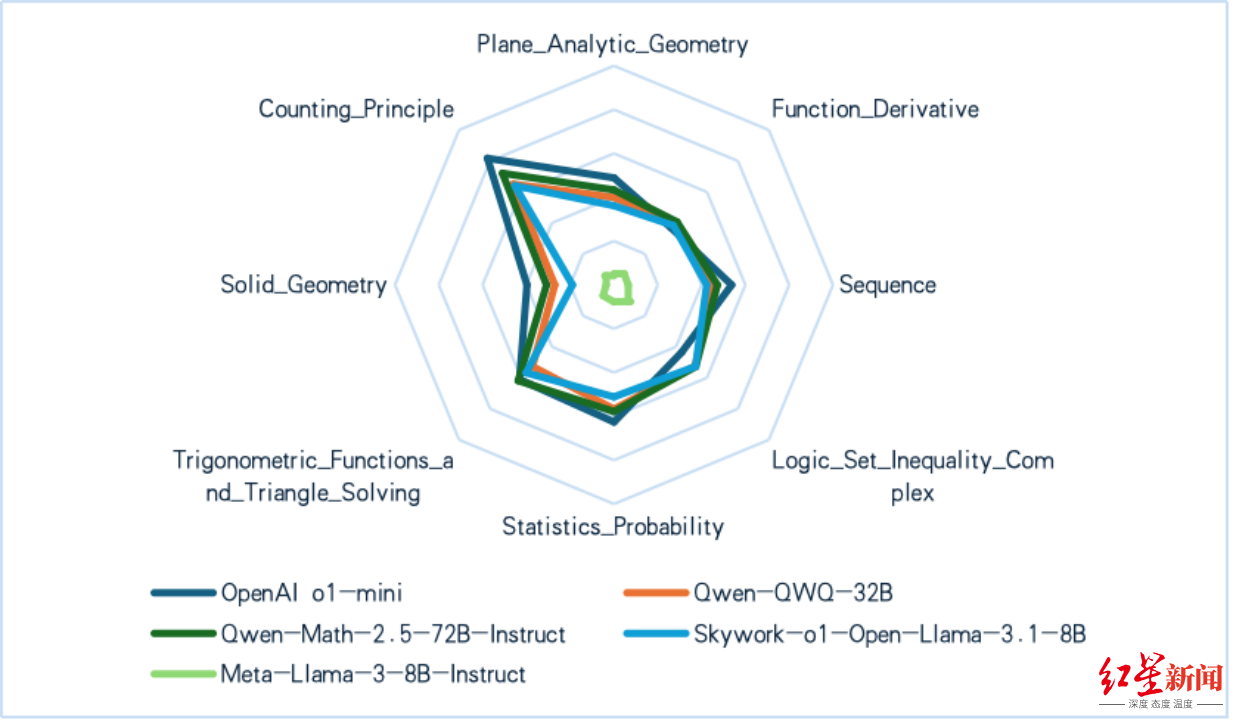
复杂推理模型在高考数学推理中展现出显著进步,小型模型能力接近大型模型,闭源模型OpenAI o1-mini在综合准确率上领先。
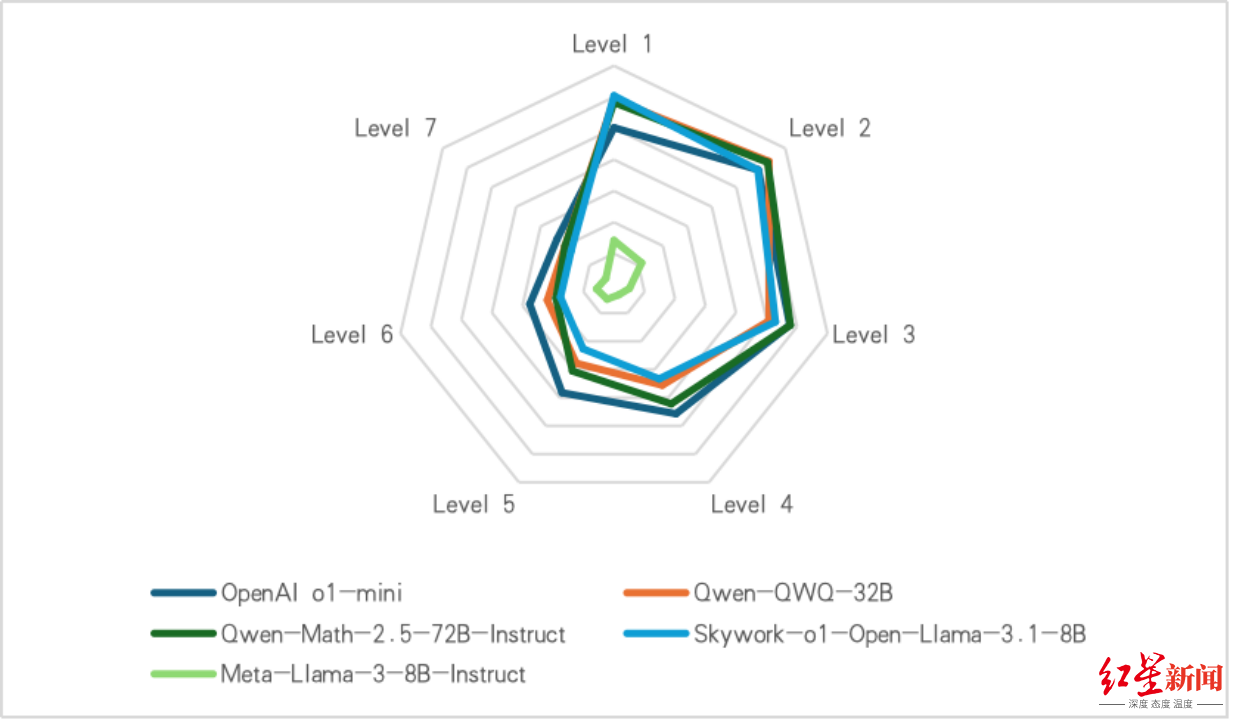
随着问题难度增加,模型性能下降,闭源模型在处理较难问题上具有优势。
六、总结
中文大模型在学科知识和数学推理方面能力大幅增强,闭源模型表现更优。在追求性能提升的同时,需重视伦理和安全性问题,构建更全面、多样化的评估体系,促进大型模型的智善协同发展。
(文章来源:红星资本局)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。







