DeepSeek-V3震撼发布,AI行业进入分布式推理时代
AI导读:
DeepSeek-V3以低廉的训练成本和卓越的性能震撼AI行业,标志着AI正式进入分布式推理时代。随着AI应用的崛起,推理算力需求不断攀升,未来AI芯片需求或将大幅增加。
日前,AI行业迎来重大突破,深度求索Deepseek-V3横空出世,震撼业界。该模型参数量高达671B,但在预训练阶段仅使用2048块GPU训练了2个月,且成本仅为557.6万美元,这一低廉的成本引发了广泛关注。与此同时,DeepSeek-V3的性能却足以比肩甚至超越其他前沿大模型。
DeepSeek-V3之所以能够实现如此高效的训练,主要得益于其采用的多头潜在注意力(MLA)和DeepSeekMoE技术。研发团队还证明了多Token预测目标(MTP)有利于提高模型性能,可用于推理加速的推测解码。此外,DeepSeek V3引入了一种创新方法,将推理能力从长思维链模型(DeepSeek R1)中蒸馏到标准模型上,显著提高了推理性能,同时保持了输出风格和长度控制。
有观点认为,DeepSeek-V3极低的训练成本或许预示着AI大模型对算力投入的需求将大幅下降,A股算力概念股也因此在27日出现下跌。然而,也有观点认为,虽然DeepSeek表现优秀,但其统计口径仅计算了预训练阶段,数据的配比需要做大量预实验,合成数据的生成和清洗也需要消耗算力。因此,训练上的降本增效并不代表算力需求会下降,而是意味着大厂可以用性价比更高的方式去探索模型的极限能力。
Lepton AI创始人兼CEO贾扬清在谈及DeepSeek-V3时指出,我们正式进入了分布式推理时代。他强调,一台单GPU机器(80×8=640G)的显存已经无法容纳所有参数,需要分布式推理来保证性能和未来扩展。中信证券研报也指出,DeepSeek-V3的发布引起了AI业内的广泛关注,其在保证模型能力的前提下,训练效率和推理速度大幅提升,意味着AI大模型的应用将逐步走向普惠,助力AI应用广泛落地。
OpenAI联合创始人兼前首席科学家Ilya Sutskever曾断言,AI预训练时代将终结。多位AI投资人、创始人和CEO们也表示,AI的Scaling Law定律的收益正在逐步衰减。包括a16z合伙人Anjney Midha、微软CEO Satya Nadella在内,AI行业CEO、研究人员和投资人们已经发出了新的判断:我们正处于一个新的Scaling Law时代——测试时间计算时代,即推理时代。这项能力让AI模型在回答问题之前能有更多时间和算力来思考,特别有希望成为下一件大事。
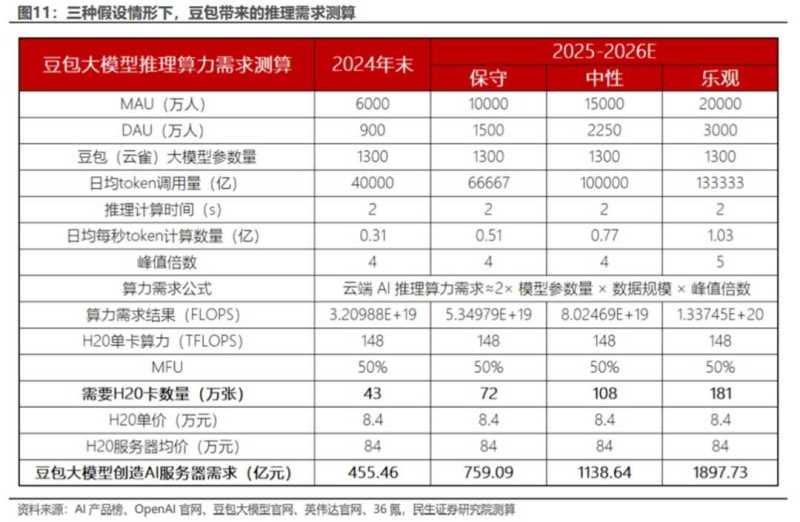
AI应用的崛起也呼唤着推理算力的提升。英伟达竞争对手、AI芯片制造商Cerebras曾解释,快速推理是解锁下一代AI应用的关键。从语音到视频,有了快速推理之后,以前无法实现的响应式智能应用程序将成为可能。以豆包为例,民生证券指出,豆包大模型应用场景的不断拓展使得对推理算力的需求不断攀升,主要集中在硬件设备算力需求、数据中心规模扩张需求、通信网络需求三方面。
分析师根据豆包的月活、日活以及日均token调用量为基础,做出保守、中性、乐观三种假设,预计豆包大模型或将带来759、1139、1898亿元的AI服务器资本开支需求。随着AI应用显著带动算力建设,分析师指出,字节算力资本开支持续攀升。此外,小米也在着手搭建自己的GPU万卡集群,对AI大模型进行大力投入。海外科技巨头也在大手笔加大资本开支,据摩根士丹利预估,海外四大科技巨头在2025年的资本开支可能高达3000亿美元。
Bloomberg Intelligence的报告指出,企业客户可能会在2025年进行更大规模的AI投资,而AI支出增长将更侧重于推理侧,以实现投资变现或提升生产力。随着端侧AI放量,豆包、ChatGPT等AI应用快速发展,多家券商研报指出,算力需求会加速从预训练向推理侧倾斜,推理有望接力训练,成为下一阶段算力需求的主要驱动力。a16z合伙人Anjney Midha表示,如果推理计算成为扩展AI模型性能的下一个领域,那么对专门用于高速推理的AI芯片的需求可能会大幅增加。
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。










