s1-32B模型挑战Deepseek,低成本高效能引发科技界热议
AI导读:
s1-32B模型以不到50美元的成本,利用16张英伟达H100 GPU,成功研发出,在数学及编码能力测试中与Deepseek的R1模型等表现不相上下,成为科技界热议话题。本文探讨其真实成本、性能及背后技术细节。
2月6日,据外媒最新报道,斯坦福大学与华盛顿大学的科研团队,在李飞飞等杰出研究者的带领下,以惊人的低成本——不到50美元,利用16张英伟达H100 GPU,仅耗时26分钟,就成功研发出了一款名为s1-32B的人工智能推理模型。这一成果再次刷新了AI界对于成本与效率的认知。
李飞飞团队在论文《s1: Simple test-time scaling》中详细阐述了该模型的性能。据研究显示,s1-32B在数学及编码能力测试中,与业界领先的OpenAI的o1模型和Deepseek的R1模型相比,表现毫不逊色,甚至在某些竞赛数学问题上的表现优于o1-preview达27%。这一突破性进展,使得s1-32B模型成为了继DeepSeek之后,又一个在科技界掀起波澜的“性价比之王”。
然而,关于s1-32B模型的真实成本及其性能表现,业内也存在不少疑问。复旦大学计算机学院的副教授郑骁庆在接受采访时指出,像DeepSeek这样的公司在探索高效整合方案时,往往需要大量的前期研究与消融实验,这意味着高昂的初期投入。因此,s1-32B模型所宣称的50美元成本,可能并未涵盖所有相关的研发与实验费用。
针对成本问题,参与该项目的斯坦福大学研究员尼克拉斯·穆宁霍夫表示,如今只需约20美元就能租到所需的计算资源。但值得注意的是,s1-32B模型的打造并非从零开始,而是基于阿里通义千问Qwen2.5-32B-Instruct模型进行了监督微调。因此,微调模型与全新训练模型的成本差异显著。
此外,关于s1-32B模型是否真正超越了OpenAI的o1和DeepSeek-R1,也引发了业内的广泛讨论。虽然李飞飞团队的研究结果显示,s1-32B在某些测试集上的表现优于o1-preview,但并未超过“满血版”的o1和DeepSeek-R1。这一发现揭示了AI模型性能比较的复杂性,也提醒我们在评估模型时需谨慎对待各种测试结果。
除了成本与性能问题外,李飞飞团队的研究还聚焦于测试时拓展(test-time scaling)技术。该技术通过在模型推理阶段进行多步推理来提高性能。通过预算强制策略,研究团队成功控制了模型的思考时间和操作步数,从而实现了推理结果的逐步优化。这一技术的突破,为提升AI模型性能提供了新的思路。
同时,李飞飞团队还构建了一个高质量的数据集s1K,该数据集包含59029道高质量题目,覆盖50个领域。通过严格的筛选和验证,研究团队最终得到了包含1000个样本的s1K数据集。这一数据集的构建,不仅为s1-32B模型的训练提供了有力支持,也展示了高质量数据在AI模型研发中的重要性。
综上所述,s1-32B模型的诞生不仅再次证明了低成本高效能在AI领域的可行性,也为未来AI模型的发展提供了新的方向。然而,关于其真实成本、性能表现以及技术细节的讨论仍将继续,期待未来能有更多关于s1-32B模型的深入研究与应用。

图片来源:论文《s1: Simple test-time scaling》
图片来源:X
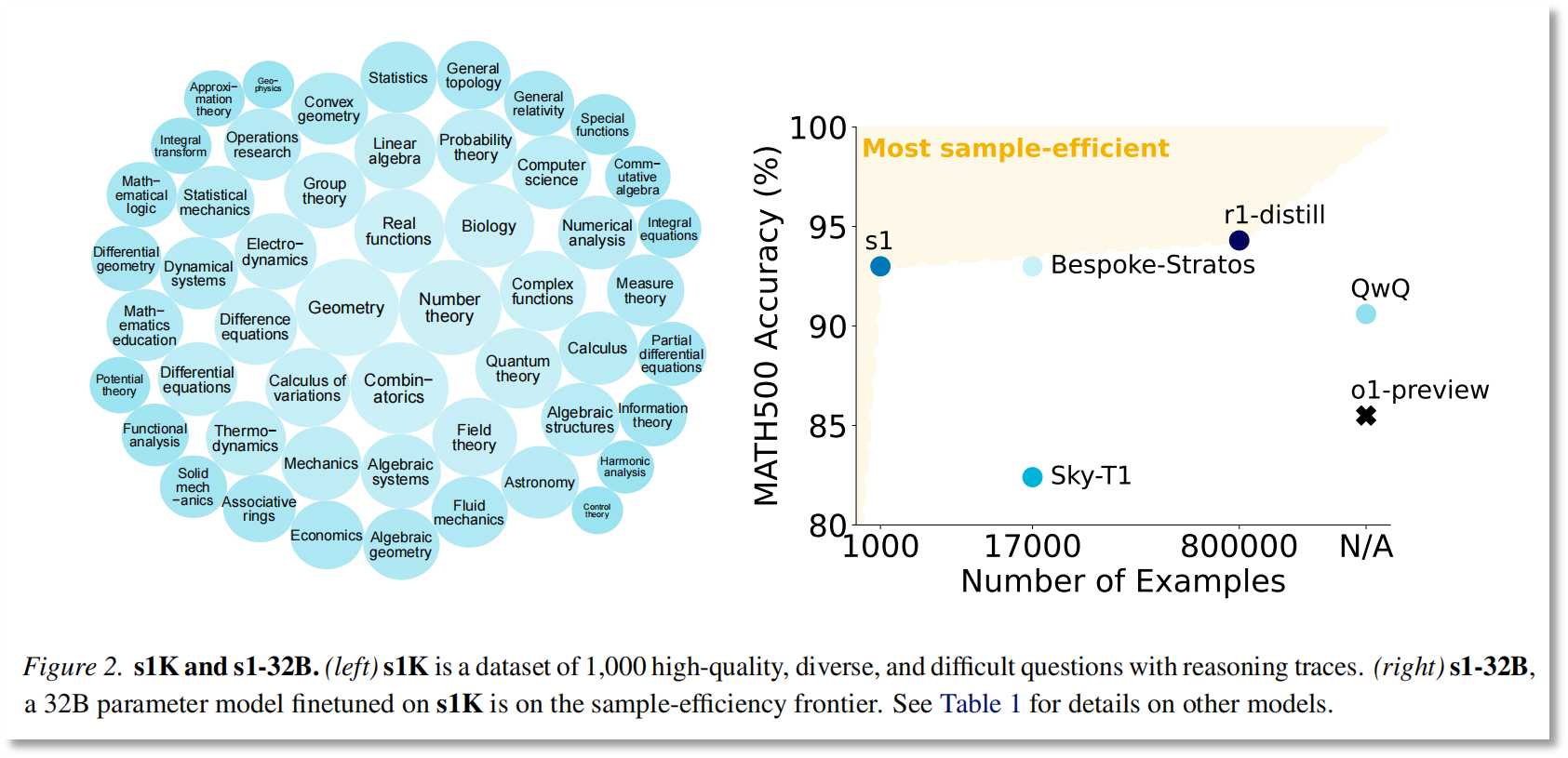
图片来源:论文《s1: Simple test-time scaling》
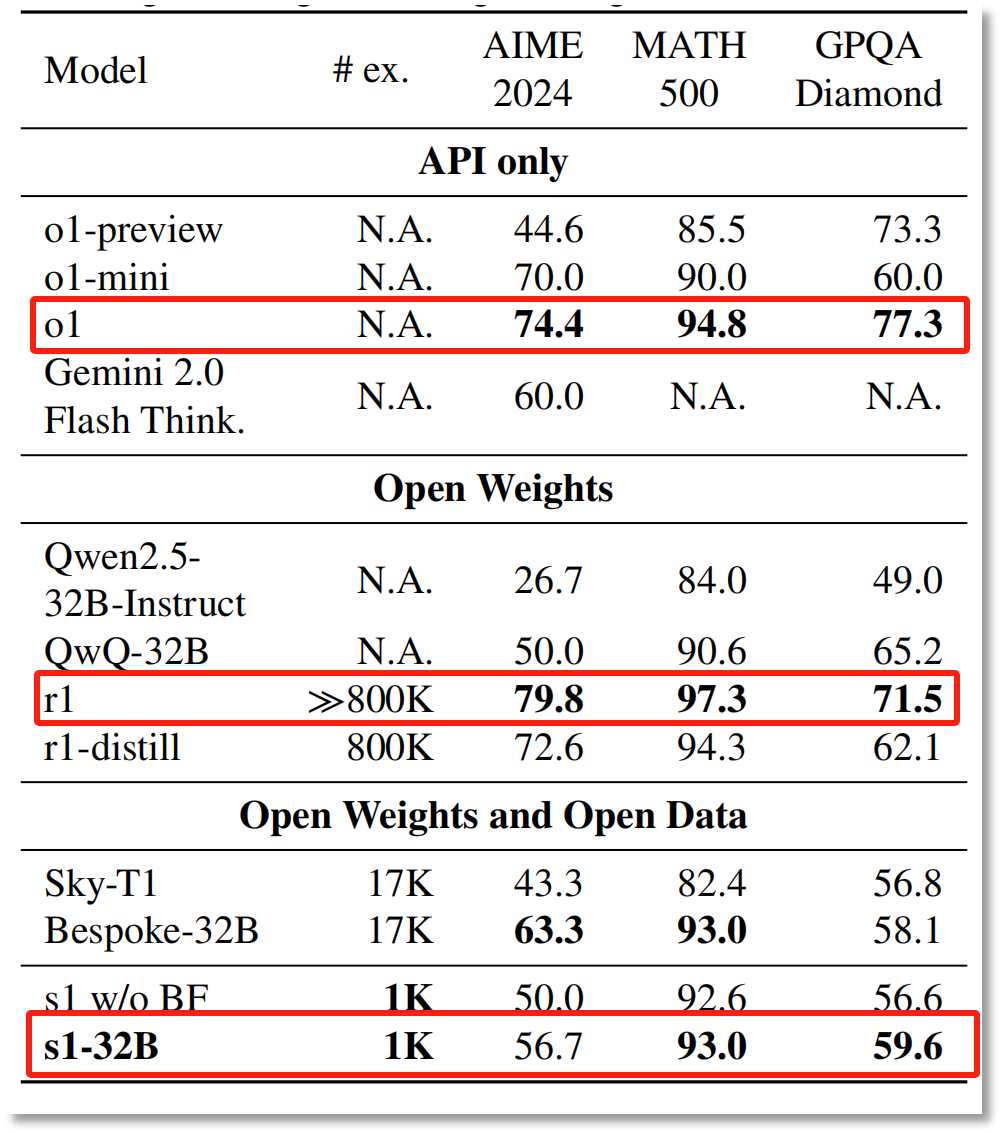
图片来源:论文《s1: Simple test-time scaling》

图片来源:论文《s1: Simple test-time scaling》
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。






