Qwen2.5-Max登顶Chatbot Arena非推理类中国大模型冠军
AI导读:
2月4日凌晨,Chatbot Arena公布最新大模型盲测榜单,Qwen2.5-Max以1332分位列全球第七,成为非推理类中国大模型冠军。在数学、编程等单项能力上排名第一,硬提示方面排名第二。企业可在阿里云百炼调用API服务,开发者可在Qwen Chat平台免费体验。
2025年2月4日凌晨,备受瞩目的三方基准测试平台Chatbot Arena揭晓了最新的大模型盲测榜单,令人瞩目的是,阿里巴巴阿里云通义团队于一周前刚刚发布的Qwen2.5-Max模型,在此次测试中异军突起,以1332分的优异成绩成功跻身全球第七,同时,它也成为了非推理类中国大模型中的佼佼者。
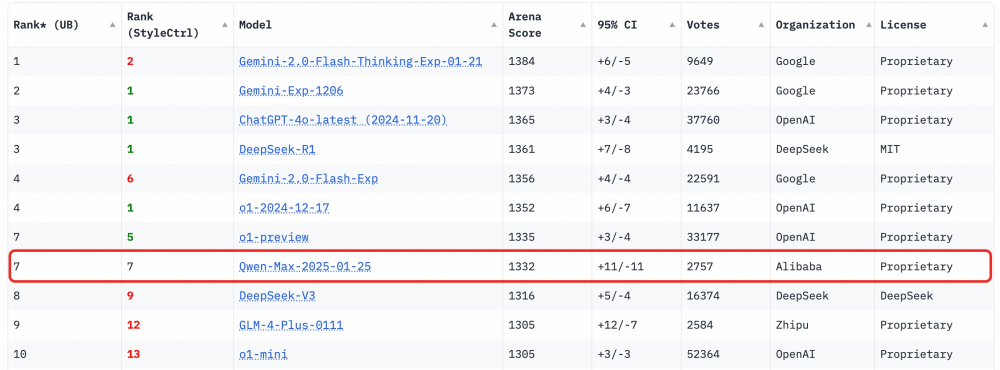
在单项能力比拼中,Qwen2.5-Max更是展现出了非凡的实力,不仅在数学和编程领域独占鳌头,还在硬提示(Hard prompts)方面紧随榜首,位居第二。这一连串的亮眼表现,无疑为Qwen2.5-Max赢得了业界的广泛关注和赞誉。
据悉,Chatbot Arena是由LMSYS Org倾力打造的大模型性能测试平台,目前该平台已集成了多达190种模型。该榜单通过匿名的方式将大模型进行两两组队,交由用户进行盲测,用户则根据自己的真实对话体验对模型能力进行投票。正是这样公正、透明的测试机制,使得Chatbot Arena LLM Leaderboard成为了业界公认的最具权威性的榜单之一,也吸引了全球顶级大模型在此一决高下。
ChatBot Arena官方对Qwen2.5-Max给予了高度评价,称其在多个领域,尤其是专业技术领域(如编程、数学、硬提示等)展现出了强劲的实力。这一评价无疑为Qwen2.5-Max的卓越性能提供了有力的佐证。
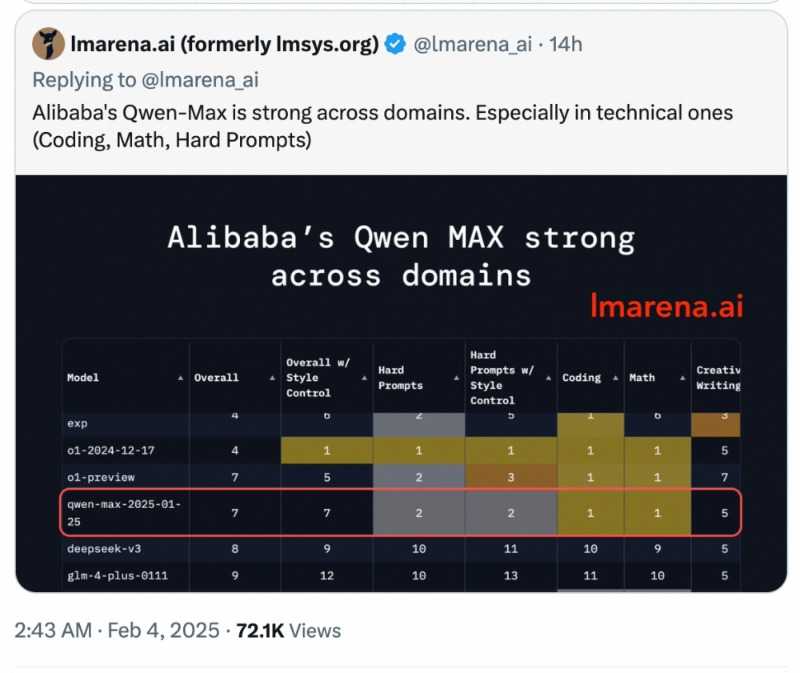
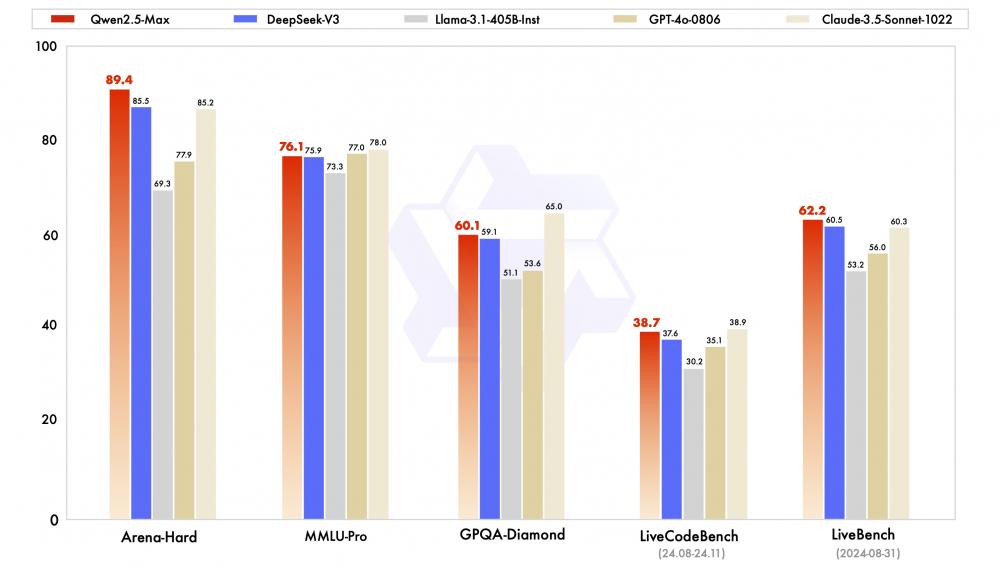
作为阿里云通义团队的最新MoE模型,Qwen2.5-Max自发布以来便备受瞩目。在Arena-Hard、LiveBench、LiveCodeBench、GPQA-Diamond及MMLU-Pro等主流基准测试中,Qwen2.5-Max与Claude-3.5-Sonnet并驾齐驱,甚至在某些方面全面超越了GPT-4o、DeepSeek-V3及Llama-3.1-405B等模型,展现出了其卓越的性能和强大的竞争力。
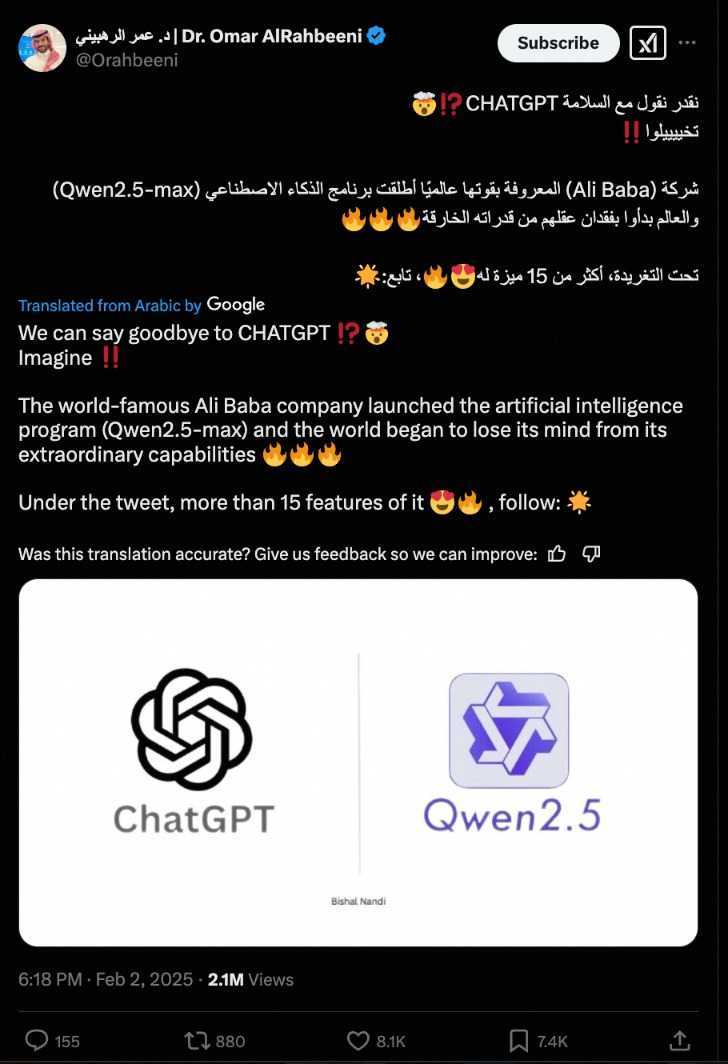
Qwen2.5-Max的发布在海内外大模型社区引发了热烈讨论。ChatBot Arena官方在推特上发文称,以Qwen2.5-Max为代表的中国大模型正在迅速崛起,成为全球大模型领域的重要力量。许多从业者对新模型的强大性能表示惊叹,并兴奋地表示:“我们可以告别ChatGPT了!”
目前,企业用户可以在阿里云百炼平台上调用Qwen2.5-Max模型的API服务,享受其带来的高效、便捷的对话体验。同时,开发者也可以在Qwen Chat平台中免费体验这一最新模型,感受其强大的功能和卓越的性能。
此次Qwen2.5-Max在Chatbot Arena盲测榜单中的优异表现,不仅展示了中国大模型的强大实力,也为中国AI技术的发展注入了新的活力和信心。我们有理由相信,在未来的发展中,中国AI技术将继续保持强劲势头,为全球AI领域的发展贡献更多智慧和力量。
(文章来源:21世纪经济报道)

郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。










