DeepSeek冲击AI产业格局,英伟达市值暴跌引发行业震动
AI导读:
DeepSeek公司开源其推理模型DeepSeek-R1,对英伟达等巨头造成巨大冲击,引发全球科技界广泛关注和讨论。DeepSeek-R1在性能、价格和开源方面均表现出色,挑战了现有的AI产业格局。同时,OpenAI也感受到了压力,推出了全新推理模型o3-mini并开放给免费用户。DeepSeek的出现和崛起,引发了关于AI未来的思考。
2025年1月中旬,英伟达CEO黄仁勋的中国之行成为科技界焦点,但与此同时,一场足以撼动AI产业格局的风暴正在杭州悄然酝酿。一家名为深度求索(Deepseek)的中国公司,于1月20日悄然开源了其推理模型DeepSeek-R1,这一举动随后引发了全球科技界的广泛关注和讨论。
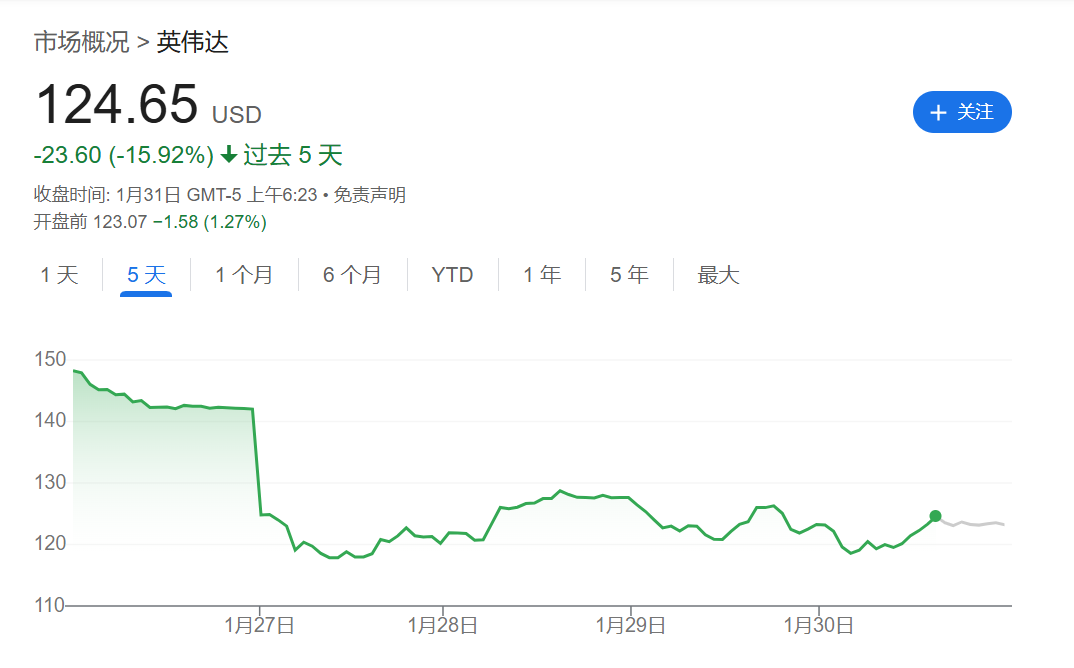
DeepSeek-R1的开源,对英伟达造成了巨大冲击。在短短一周内,英伟达市值蒸发了5520亿美元,硅谷巨头和华尔街均陷入焦虑。摩根大通分析师表示,DeepSeek已成为科技圈、投资圈和媒体圈讨论的热点。市场评论员甚至预言,DeepSeek将成为美国股市的最大威胁。
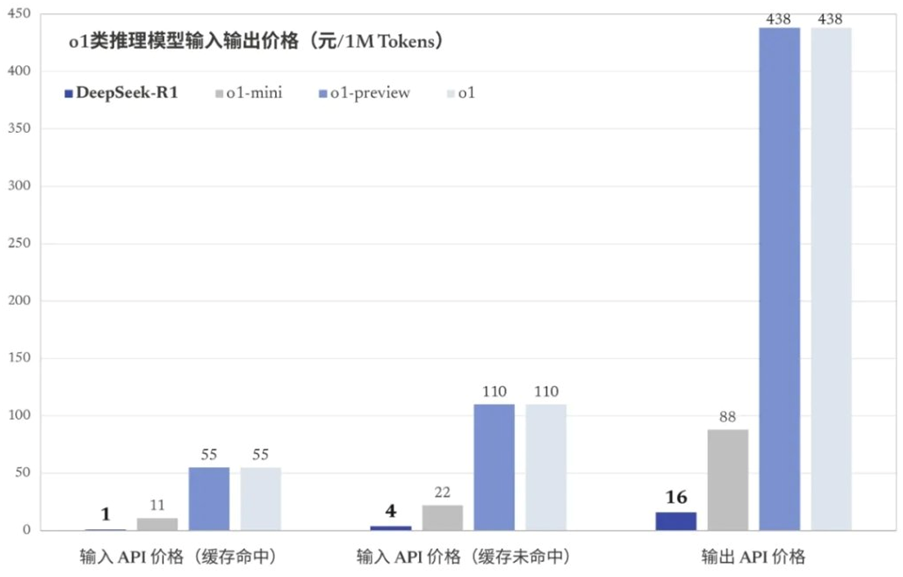
DeepSeek-R1的冲击主要来自三个方面:性能、价格和开源。在性能上,DeepSeek-R1与OpenAI的ChatGPT o1并列,甚至在高难度领域位列第一。在价格上,DeepSeek-R1提供了极为低廉的API端口费用,仅为o1的2%~3%,且移动应用和网页端免费。在开源方面,DeepSeek-R1的完全开源打破了大型语言模型被少数公司垄断的局面,将AI技术交到了广大开发者和研究人员的手中。
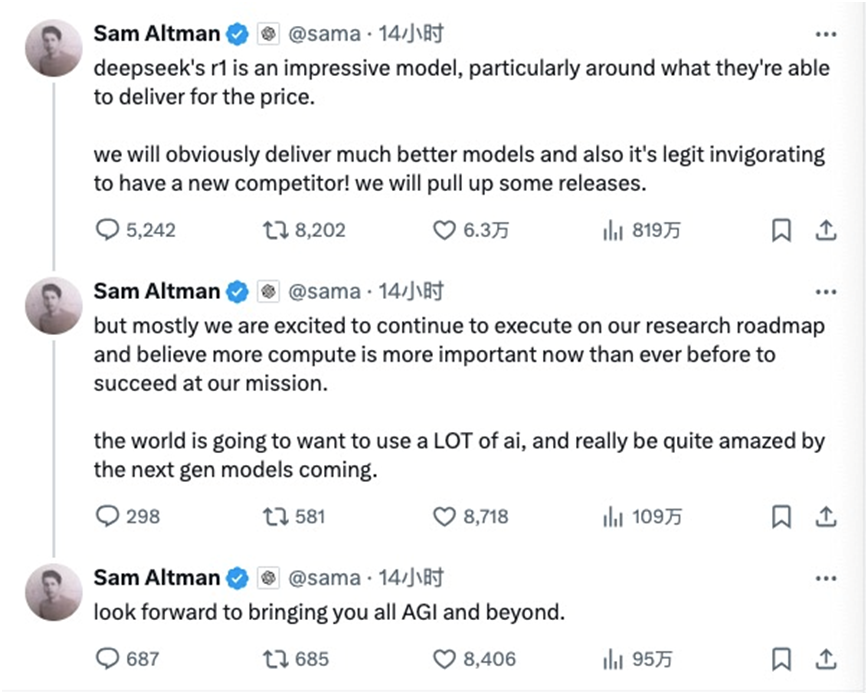
随着DeepSeek-R1的崛起,OpenAI也感受到了压力。1月31日,OpenAI正式推出了全新推理模型o3-mini,并首次向免费用户开放。OpenAI首席执行官Sam Altman在回答网友问题时,罕见承认OpenAI过去在开源方面一直站在“历史错误的一边”,并表示需要想出一个不同的开源策略。
DeepSeek-R1的训练成本虽未公布,但根据分析,其低成本主要得益于数据蒸馏技术的使用。然而,数据蒸馏技术在行业内充满争议,南洋理工大学研究人员表示,蒸馏技术存在一个巨大缺陷,就是被训练的模型(即“学生模型”)没法真正超越“教师模型”。尽管如此,DeepSeek-V3的创新性仍不容忽视,它同时使用了FP8、MLA和MoE三种技术,使得模型在保持高性能的同时,降低了训练成本。
DeepSeek的出现,不仅挑战了英伟达等巨头的地位,也引发了关于AI技术路线的争议。传统上,监督微调(SFT)作为大模型训练的核心环节,被认为是ChatGPT成功的关键技术路径。然而,DeepSeek-R1却完全摒弃了SFT环节,而完全依赖强化学习(RL)训练。这一突破为AI的自主学习范式提供了重要的实践范例。
DeepSeek的创始人梁文锋被誉为“一个更极致的中国技术理想主义者”。他坚持走原创路线,不做垂类和应用,而是专注于研究和探索。梁文锋认为,中国AI与美国之间的差距在于原创和模仿之差,只有坚持原创,才能成为真正的领导者。
随着DeepSeek-R1的开源和崛起,科技巨头如微软、AWS和英伟达等纷纷接入其模型服务。微软将DeepSeek-R1模型添加到其Azure AI Foundry,AWS宣布用户可以在其平台上部署DeepSeek-R1模型,英伟达也将DeepSeek-R1模型作为NVIDIA NIM微服务预览版发布。这些巨头的加入,进一步推动了DeepSeek的发展和应用。
DeepSeek的出现和崛起,不仅挑战了现有的AI产业格局,也引发了关于AI未来的思考。是继续烧钱豪赌,还是让AI成果商业化、平民化和普惠化?随着训练成本降低、技术成熟以及开源,大语言模型将愈发成为一种普通产品。未来,AI世界将呈现怎样的格局?是“大力出奇迹”的继续狂飙,还是“聪明”技术的异军突起?这一切仍有待观察。


郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。










