DeepSeek“破圈”:以低成本训练方式引领AI新潮流
AI导读:
DeepSeek凭借低成本的训练方式在全球人工智能市场掀起波澜,霸榜刷屏美股,成为引爆AI圈的东方“黑马”。其最新发布的DeepSeek-V3和R1两款大模型产品引发广泛关注,有望为具身智能行业带来新的解法和思路。
在蛇年春节前夕,人工智能领域的黑马Deepseek“破圈”而出,以其低成本的训练方式在全球人工智能市场掀起波澜,不仅在美股市场霸榜刷屏,更成为了AI圈内引爆话题的东方力量。
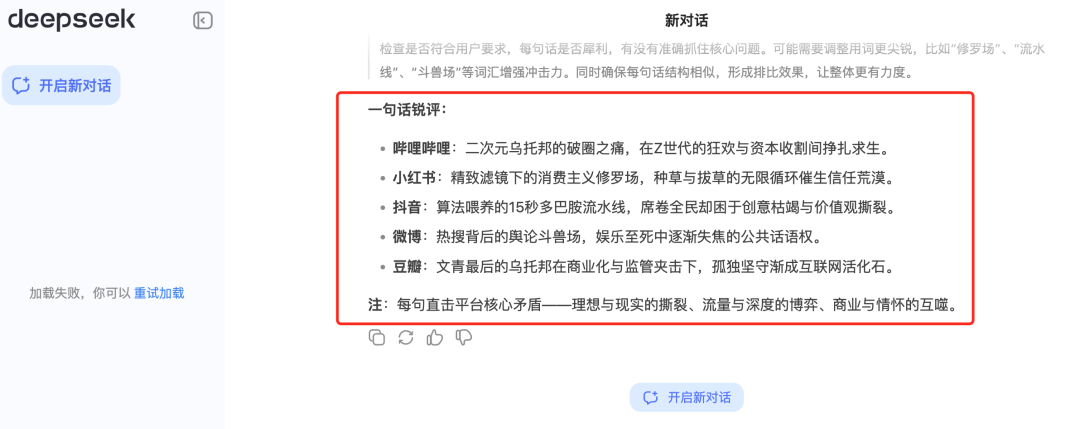
28日,#DeepSeek锐评#的话题迅速冲上热搜,其犀利的评价文风引发了广泛关注。记者尝试让AI DeepSeek对小红书、抖音等社交媒体以及各国产手机品牌进行锐评,经过两次深度思考,总计用时46秒后,DeepSeek给出了或许是世界上最聪明的AI之一的独特见解。
以下是DeepSeek的“毒舌”点评:



成立于2023年7月的DeepSeek并非一夜成名,而是凭借其DeepSeek-V2版本开始在硅谷崭露头角,被视为东方的神秘力量。近期,随着DeepSeek-V3和R1两款大模型产品的相继发布,该公司再次成为热议的焦点。2024年年末,DeepSeek-V3大模型一经发布,便迅速吸引了全球人工智能领域的目光,其以极低的训练成本实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能,让业界惊叹不已。
今年1月20日,DeepSeek再度发力,发布了最新开源模型DeepSeek R1,该模型的研发耗时不到两个月,却具备了所有熟悉的功能,对标OpenAI o1模型,但运行成本仅为OpenAI、谷歌或Meta的流行人工智能模型的极小部分。DeepSeek表示,其基础模型的计算能力仅花费了不到600万美元,而美国公司在人工智能技术上则花费了数亿或数十亿美元。这一举措不仅展现了DeepSeek在高性能与低成本之间的平衡能力,更在国内大模型行业掀起了真正意义上的“降价潮”,DeepSeek因此被誉为“价格屠夫”,也有人称之为“AI界的拼多多”。
DeepSeek的“横空出世”为具身智能行业带来了新的解法和思路。高工机器人产业研究所所长卢瀚宸指出,结合当前国内具身智能和人形机器人的痛点和短板,DeepSeek有望在基础模型和前沿创新领域带来颠覆性影响。萨摩耶云科技集团AI机器人研究员郑扬洋也表示,DeepSeek的推理能力能够加快机器人决策和响应的进程,使得机器人不仅能够看到物体,更能理解更深层次的意图与背景信息,这意味着机器人看到和理解之间的大雾正在逐渐消失。
根据披露的数据,DeepSeek-R1在三维空间推理方面表现出87.6%的准确率,并在跨模态意图理解方面达到了91.2%的F1值。郑扬洋认为,DeepSeek的开源模型和详细技术报告的提供,将有助于其他研究人员和工程师快速验证和拓展该方法,从而推动通用机器人大模型的发展。随着国产厂商追赶一线模型的训练成本大幅下降,国产机器人有望通过更低的成本推动行业通用大模型的成熟。
一直以来,算力和成本都是制约具身智能大模型发展的关键因素。一位具身智能企业的技术人员表示,现行传统域控制器的算力在几TOPS到几百TOPS不等,上千TOPS甚至更多的平台并不多见。如果不能在降低成本的同时提高算力,机器人的落地仍然会面临问题。因此,DeepSeek近乎颠覆性的验证给具身智能行业带来了更多希望,算力、算法、成本的创新都有机会重新书写游戏规则。
(文章来源:新黄河,经第一财经整合)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。










