DeepSeek引发热议:AI黑马挑战硅谷巨头
AI导读:
DeepSeek发布新模型DeepSeek-R1并同步开源模型权重,引发全球AI科技圈关注。英伟达竞争对手AMD集成DeepSeek-V3模型,引发行业变革预期。DeepSeek的成功通过软件优化减少高端GPU依赖,降低AI大模型算力投入需求,对英伟达等构成潜在挑战。
DeepSeek,这家中国的AI创业公司,再次在海外科技界掀起波澜。自1月20日DeepSeek发布新模型DeepSeek-R1并同步开源模型权重以来,它已迅速吸引了全球AI科技圈的广泛关注。近期,包括《纽约时报》、《经济学人》以及《华尔街日报》在内的多家英美主流媒体纷纷报道了DeepSeek的最新研究进展,并对其模型的卓越性能给予了高度评价。CNBC更是直言:“DeepSeek-R1凭借其超越美国顶尖同类模型的性能,加之更低的成本和更少的算力消耗,已经在硅谷引发了恐慌。”
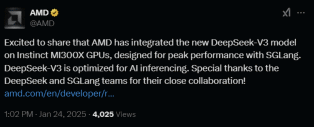
尤为引人注目的是,AMD,这家英伟达的竞争对手及知名半导体公司,昨日宣布已将DeepSeek-V3模型集成到其芯片产品Instinct MI300X GPU上,旨在与SGLang协同实现最佳性能。DeepSeek-V3针对AI推理进行了深度优化。业内人士分析指出,AMD与DeepSeek的携手合作,不仅为AI推理领域带来了新的想象空间,更有望撼动由“英伟达+OpenAI”所主导的行业格局,彻底改变现有的游戏规则。
自去年底DeepSeek-V3发布以来,业界就掀起了关于DeepSeek如何打破算力需求“怪圈”的热烈讨论。而近日,随着DeepSeek-R1在海外引发广泛热议,1月24日,英伟达股价再度大跌3.12%。
值得一提的是,1月26日,部分网友反映DeepSeek出现访问问题,提示服务器繁忙。然而,在14时56分,证券时报记者实测发现,DeepSeek已恢复正常使用。
据媒体报道,DeepSeek对此回应称,1月26日下午确实出现了局部服务波动,但问题已在极短时间内得到解决。此次事件可能与新模型发布后访问量激增有关,而官方状态页并未将其标记为事故。
DeepSeek:让硅谷巨头坐立不安的黑马
据DeepSeek介绍,其最新发布的DeepSeek-R1模型在后训练阶段大规模运用了强化学习技术,在仅有极少标注数据的情况下,显著提升了模型的推理能力。在数学、代码、自然语言推理等任务上,其性能已可与OpenAI GPT-4正式版相媲美。
这一模型的发布,瞬间点燃了海外AI圈的热议。例如,英伟达高级研究科学家Jim Fan就在个人社交平台上发文称:“我们正身处这样一个历史时刻:一家非美国公司正在延续OpenAI最初的使命——通过真正开放的前沿研究赋能全人类。这看似不合常理,但往往最有趣的结局最可能成真。”
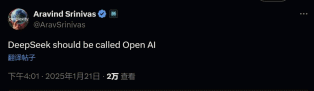
在近日举办的2025年达沃斯论坛上,AI初创公司Scale AI的创始人Alexandr Wang对DeepSeek的新模型给予了高度评价,称其表现令人印象深刻,尤其是在模型推理效率方面。他强调,我们必须认真对待来自中国的这些发展。另一家知名AI创业公司Perplexity的首席执行官Aravind Srinivas甚至直言:“DeepSeek才配叫做OpenAI。”
DeepSeek,这匹AI领域的黑马,自去年底发布DeepSeek-V3以来就吸引了硅谷的广泛关注,并因其低调的作风而被誉为“来自东方的神秘力量”。新模型的发布,更是让硅谷巨头陷入了既兴奋又紧张的状态。一则来自Meta员工在匿名社区Teamblind的爆料称,Meta的生成式人工智能团队正陷入恐慌。帖子进一步透露,目前Meta的工程师们正在疯狂拆解DeepSeek,试图复制其中的一切。
同时,由于DeepSeek擅长“小成本办大事”,通过创新架构和优化算法实现了更高经济性的训练效果和更高效的推理。DeepSeek-V3的总训练成本仅为550万美元左右,不到Llama-3 405B超6000万美元训练成本的十分之一。该爆料帖还指出,Meta管理层正面临严峻的财务压力,该生成式AI部门的数十位高管,每个人的年薪都超过了DeepSeek-V3的全部训练费用。如何向公司高层解释这种投入产出比,已成为他们的噩梦。
DeepSeek的成功不仅震动了硅谷巨头,也吸引了英美多家主流媒体的专门报道。例如,英媒《经济学人》指出:“目前训练一个美国大语言模型要花费数千万美元,而DeepSeek的支出不到600万美元。这种廉价的训练方式正随着模型设计的发展而改变整个行业,这可能导致更多针对特定用途的专业模型涌现,从而打破赢家通吃的市场格局。”

《金融时报》也发表了题为“中国一家小小的AI创业公司如何让硅谷感到震惊”的文章。文章中提到:“R1模型的发布在硅谷引发了一场激烈辩论,主题是包括Meta和Anthropic在内的资源更雄厚的美国人工智能企业能否守住技术优势。”“DeepSeek没有从外部基金筹集资金,也没有采取重大举措将其模型商业化。DeepSeek的运作方式就像早期的DeepMind,专注于研究和工程。”
股民热议:DeepSeek是否利空英伟达?
在Meta员工爆料的匿名社区Teamblind上,证券时报记者发现已有多个帖子在讨论DeepSeek。除了关于模型成本与性能等方面的技术讨论外,还有股民发起了题为“英伟达是否应该为DeepSeek感到担忧”的投票。帖子还给出了一些背景信息,提示DeepSeek仅用不到600万美元在性能并非顶尖的GPU上训练出了V3模型,效果直逼Meta的开源模型Llama。而且,其最新发布的R1模型足以媲美OpenAI的GPT-4模型。
事实上,自去年底DeepSeek发布V3模型以来,业界就注意到,DeepSeek的成功背后的更大意义在于,它能够通过软件优化,在有限的硬件资源下实现顶尖的模型性能,从而减少对高端GPU的依赖。有观点认为,DeepSeek-V3极低的训练成本预示着AI大模型对算力投入的需求将大幅下降,这无疑将对全球AI算力的核心供应商英伟达构成利空。
据证券时报记者了解,大模型主要分为训练和推理两个阶段。训练是指用大量数据来训练大模型,通常需要极高的计算能力和存储资源;而推理则是将训练好的模型应用于实际任务(如提问并生成文本、识别图片与视频等)。这两者采用的是不同的芯片。过去两年,各大厂商都在加紧训练大模型,算力主要体现在训练阶段,而模型训练正是英伟达GPU的优势所在。但随着模型基本训练成型及AI应用的爆发,算力的增长或将更侧重于推理侧。
同时,DeepSeek不仅大幅降低了模型训练成本,而且其发布的新模型R1也同步开源了模型权重,并公开了完整的训练细节,这对闭源系统的优势构成了挑战。随着DeepSeek降低AI大模型技术及使用门槛,有市场人士担忧,DeepSeek R1的崛起可能会削弱市场对英伟达AI芯片需求的预期,从而对英伟达的市场地位和战略布局产生影响。
然而,也有观点认为,DeepSeek只计算了预训练的算力消耗,但数据配比、合成数据的生成和清洗等方面也需要消耗大量算力。同时,训练成本的降低未必意味着算力需求下降,只代表模型厂商可以使用性价比更高的方式去探索模型的极限能力。中信证券研报也指出,DeepSeek-V3意味着AI大模型的应用将逐步走向普惠,助力AI应用广泛落地。同时,训练效率的大幅提升也将助力推理算力需求的高增。
(文章来源:证券时报)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。










