英伟达H100芯片组在MLPerf测试中刷新纪录
AI导读:
英伟达H100芯片组在MLPerf基准评测中刷新了所有组别的纪录,成为唯一能够完成所有测试的硬件平台。在GPT-3大语言模型训练测试中,英伟达与CoreWeave合作,创造了新的业界标准。
当地时间周二,机器学习及人工智能领域开放产业联盟MLCommons公布了MLPerf基准评测的最新数据。在人工智能算力表现的测试中,英伟达H100芯片组表现出色,不仅刷新了所有组别的纪录,还成为唯一能够完成所有测试的硬件平台,彰显了其卓越的性能。
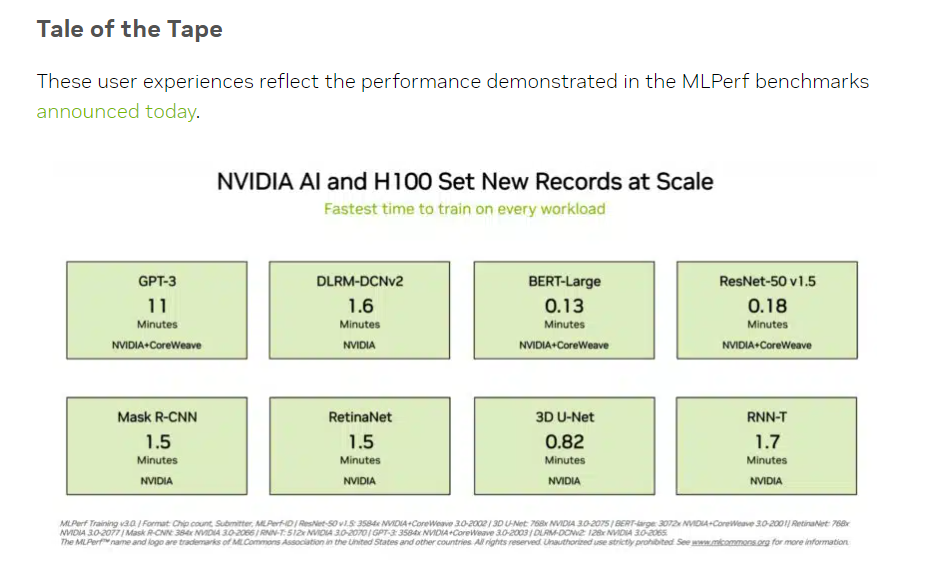
(来源:英伟达、MLCommons)
MLPerf由学术界、实验室和产业界的领袖组成,其发布的AI性能评测基准在国际上享有权威地位。Training v3.0版本涵盖了视觉、语言和推荐系统等多个领域,共包含8种不同的负载。这些负载旨在测试设备供应商完成基准任务所需的时间。

(Training v3.0训练基准,来源:MLCommons)
在备受投资者关注的大语言模型训练测试中,英伟达和GPU云算力平台CoreWeave共同创造了新的业界标准。他们利用896个英特尔至强8462Y+处理器和3584个英伟达H100芯片,仅用时10.94分钟就完成了基于GPT-3的大语言模型训练任务,展示了强大的算力实力。
除了英伟达外,英特尔的产品组合也在该测试中获得了评测数据。由96个至强8380处理器和96个Habana Gaudi2 AI芯片构建的系统,完成同样测试的时间为311.94分钟。然而,与之相比,使用768个H100芯片的平台仅需45.6分钟即可完成测试,进一步凸显了英伟达的优势。
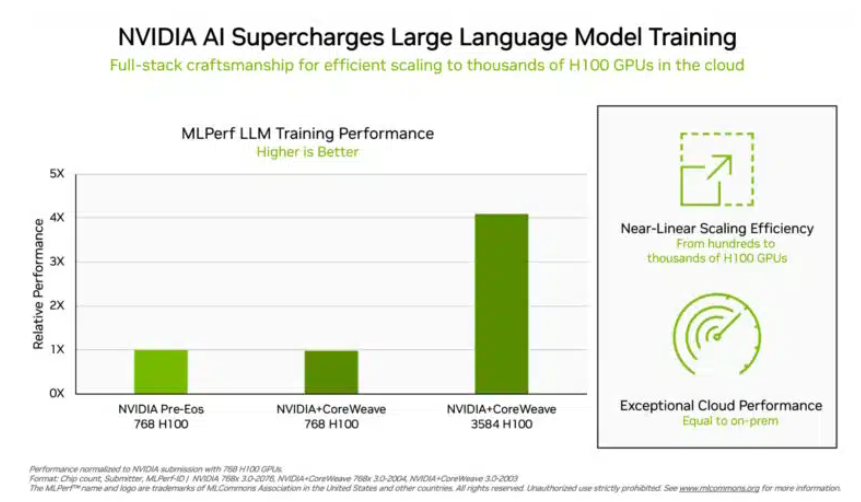
(芯片越多数据越好看,来源:英伟达)
对于测试结果,英特尔表示仍有提升空间。他们指出,通过增加芯片数量,可以进一步提高运算速度。英特尔AI产品高级主管Jordan Plawner透露,Habana的运算结果未来有望实现1.5倍至2倍的提升。尽管Plawner未透露Habana Gaudi2的具体售价,但他表示业界需要第二家厂商提供AI训练芯片,而MLPerf的数据表明英特尔具备满足这一需求的能力。
此外,在中国投资者更为熟悉的BERT-Large模型训练中,英伟达和CoreWeave再次刷新了记录,将测试时间缩短至极端的0.13分钟。在64卡的情况下,测试数据也达到了0.89分钟。BERT模型中的Transformer结构已成为当前主流大模型的基础架构,这一成绩无疑进一步证明了英伟达在AI领域的领先地位。
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。








