DeepSeek大模型崛起:高性能低成本引领AI新潮流
AI导读:
中国AI企业DeepSeek自研的大模型DeepSeek-R1在多项国际评测中表现突出,凭借高性能、低成本及开源模式备受瞩目。其崛起标志着中国大模型技术达到新台阶,为全球AI竞争注入新活力。
近日,中国AI领域迎来了一颗璀璨新星——Deepseek。这家企业凭借自研的大模型DeepSeek-R1,在多项国际评测中大放异彩,备受国内外市场瞩目。据传,Meta等全球科技巨头正紧锣密鼓地研究DeepSeek,而该公司在1月26日还经历了短暂的股价闪崩风波。
1月24日,国外知名大模型评测平台Arena公布的数据显示,DeepSeek-R1在基准测试中跃升至全类别大模型第三位,尤其在风格控制类模型(StyleCtrl)分类中,与OpenAI o1并驾齐驱,同列榜首。其竞技场得分高达1357分,略胜一筹于OpenAI o1的1352分。此前,DeepSeek已公开宣布,DeepSeek-R1在数学、代码、自然语言推理等领域的表现,足以与OpenAI o1正式版相媲美。
业内人士指出,DeepSeek凭借其低成本、高性能及开源模式,为中国AI产业的蓬勃发展注入了新鲜血液,引领着行业加速前行。
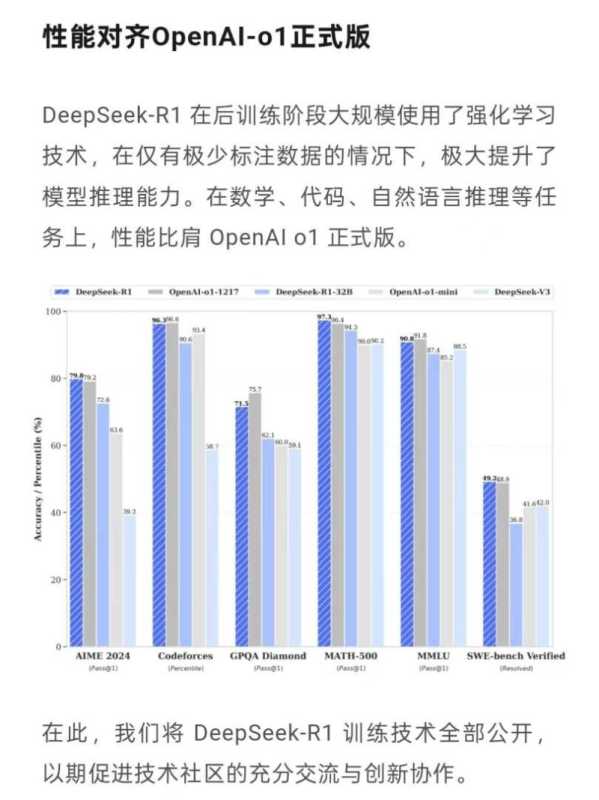
来源:DeepSeek公众号
高性能低成本开源优势显著
萨摩耶云科技集团首席经济学家郑磊分析称,DeepSeek之所以能够迅速走红,关键在于其卓越的性能与低廉的成本。DeepSeek透露,R1在后训练阶段广泛采用了强化学习技术,即便在标注数据极为有限的情况下,也极大提升了模型的推理能力。这一卓越性能不仅引起了科技界的广泛关注,更让投资界看到了其巨大的商业价值。
尤为值得一提的是,DeepSeek R1的成本优势极为明显。据悉,R1的预训练费用仅为557.6万美元,不足OpenAI GPT-4o模型训练成本的十分之一。同时,DeepSeek还公布了其API的定价策略:每百万输入tokens仅需1元(缓存命中)/4元(缓存未命中),每百万输出tokens则为16元。这一收费标准约为OpenAI o1运行成本的三十分之一,因此,DeepSeek被形象地誉为AI界的“拼多多”。

北京社科院副研究员王鹏表示:“DeepSeek以低成本实现高性能AI模型,使其在市场竞争中占据了显著优势。这种成本效益比无疑将吸引大量企业和个人用户选择其产品和服务。”
传统的闭源大模型往往需要巨额的算力资源和资金投入,使得中小企业和个人开发者望而却步。而DeepSeek的开源模式则打破了这一壁垒,让更多人有机会接触到先进的AI技术,从而推动AI技术的更广泛应用。随着AI技术的不断突破和开放共享策略的实施,DeepSeek有望吸引更多开发者加入,共同构建一个繁荣的生态系统。
成本降低助力大模型应用普及
郑磊直言不讳地指出,DeepSeek对硬件市场产生了深远影响,因为它有望降低人工智能模型的硬件成本,进而推动人工智能技术的快速发展。与此同时,随着成本的降低,大模型的应用范围将更加广泛,这将进一步促进人工智能技术在医疗保健、金融、物流、自动驾驶等多个行业的应用。
业内普遍认为,DeepSeek的崛起标志着中国在大模型技术方面取得了重大突破。王鹏强调,其高性能、低成本的AI模型在国际市场上展现出显著优势,这不仅彰显了中国在大模型技术研发方面的实力和创新能力,也为中国在全球AI竞争中赢得了更多的话语权和影响力。
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。




